
こんにちは、ServiceNow担当のヒロトです。
この記事では、ServiceNowのイベント管理アプリケーションについてご紹介します。
この記事では、ServiceNowのイベント管理アプリケーションについてご紹介します。
Event Managementとは
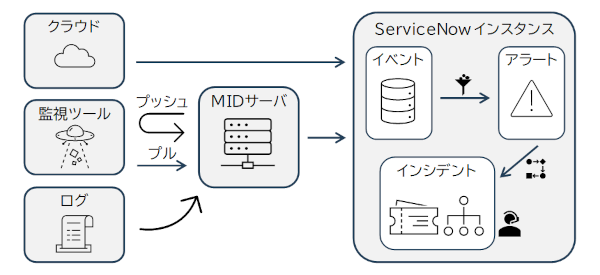
Event Managementは、ServiceNowの製品分類のITOM Healthに分類されています。組織ネットワーク内のITインフラの健全性を監視して、常に正常な状態を維持し続けることを目的とした機能となります。
はじめに注意すべき点として、ServiceNowには独自の監視ツールはありません。したがって、アラートを監視するには外部監視ツールと統合する必要があります。Event Managementは外部監視ツールからのイベントを受信し、イベントルールとアラート管理ルールに基づいてアラートを生成します。
イベントは上流のツールから送信される障害や警告などの生データを指し、イベントに対して何らかのアクションが必要と判定したものがアラートへと昇格します。イベントレコードの特徴は検出元となったソース毎に、付帯項目に差がある点で、アラートレコードの特徴はCMDBのCI情報に引き当て済みである点です。
期待できる導入効果
監視業務においての主役はあくまでも各社の監視ツールです。監視ツール単独であっても、機器のインベントリ情報を格納できたり、障害時の自動復旧も実行できたりと十分な機能を有した製品も多いかと思います。では、ServiceNowを導入することでどのような効果が期待できるのでしょうか。
その答えは、ServiceNowのコンセプトである「企業活動におけるさまざまな業務・サービスを単一プラットフォーム上に統合し、業務の標準化・可視化・自動化」の通りに、ハブとしての効果だと考えています。ServiceNowが複数サービスからのイベント取得のハブとして統合でき、CMDBがインスタンス内のさまざまな機能間の情報を繋ぐハブとして利活用できます。
また、ワークフロー、ダッシュボード、ポータルなどの共通機能を活用したり、Low-Codeプラットフォームでの拡張性によって、さらに導入の価値を高めることができます。
その答えは、ServiceNowのコンセプトである「企業活動におけるさまざまな業務・サービスを単一プラットフォーム上に統合し、業務の標準化・可視化・自動化」の通りに、ハブとしての効果だと考えています。ServiceNowが複数サービスからのイベント取得のハブとして統合でき、CMDBがインスタンス内のさまざまな機能間の情報を繋ぐハブとして利活用できます。
また、ワークフロー、ダッシュボード、ポータルなどの共通機能を活用したり、Low-Codeプラットフォームでの拡張性によって、さらに導入の価値を高めることができます。
利用可能なコネクタ群
Event Management には、外部デバイスからイベントをプルまたはプッシュするための多くのコネクタが用意されています。既にいずれかの監視ツールを利用されている場合は、ServiceNowの導入は比較的容易に実現できます。
【利用可能なプルコネクタ】
Azure Monitor、HPOM、Hyperic、LogicMonitor、IBM Netcool、Icinga2、Apache Kafka、NagiosXI、NNMi、OBM、OMi、Op5、Opsview、PRTG、SAP Solution Manager、SCOM、SolarWinds、vCenter、vRealize、Zabbix
【利用可能なプッシュコネクタ】
AWS、Azure、BMC TrueSight、New Relic、Dynatrace、Datadog、Catchpoint、Google Cloud Platform (GCP)、Logicmonitor、Oracle Cloud、Prometheus、Sentry、SNMP traps、ThousandEyes、Email、Oracle Enterprise Manager、Grafana、EIF listener、Honeycomb、Instana、Scout APM events、Panopta
イベントルールの設定
ここからは主要な設定箇所について説明します。
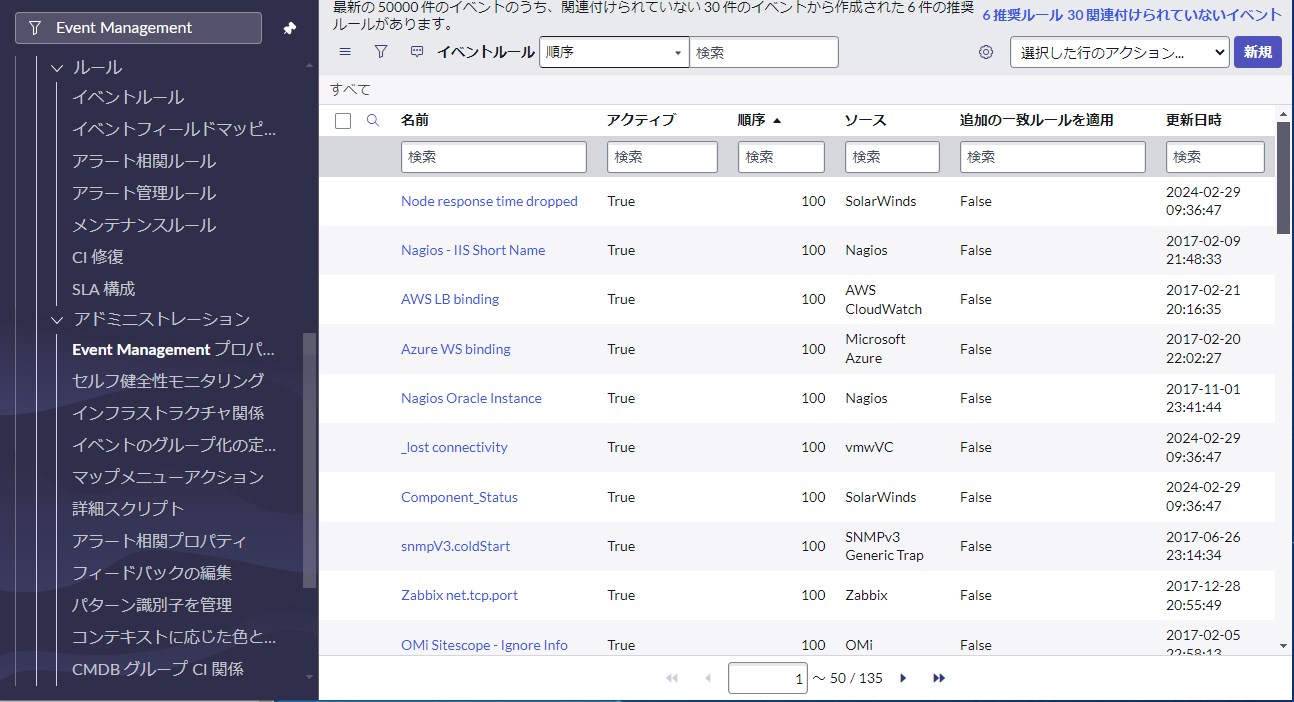
[Event Management] > [Rules] > [Event Rules]から新規のイベントルールを作成します。
受信した外部イベントの中に、ルール未定義のものが存在する場合にはインスタンスから自動でルール提案も行われるため、運用開始後にルールを追加する際に役立ちます。
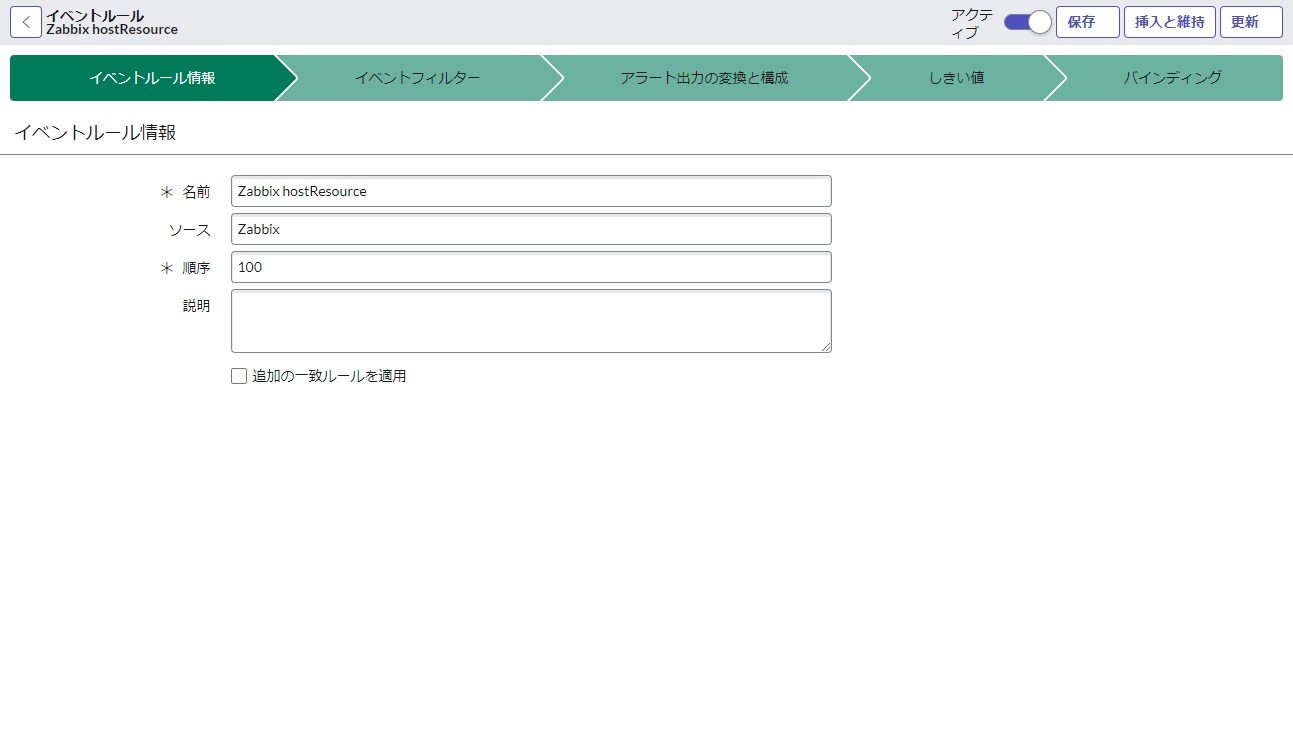
フォーム画面では専用のイベントルールデザイナーでルール定義を編集します。
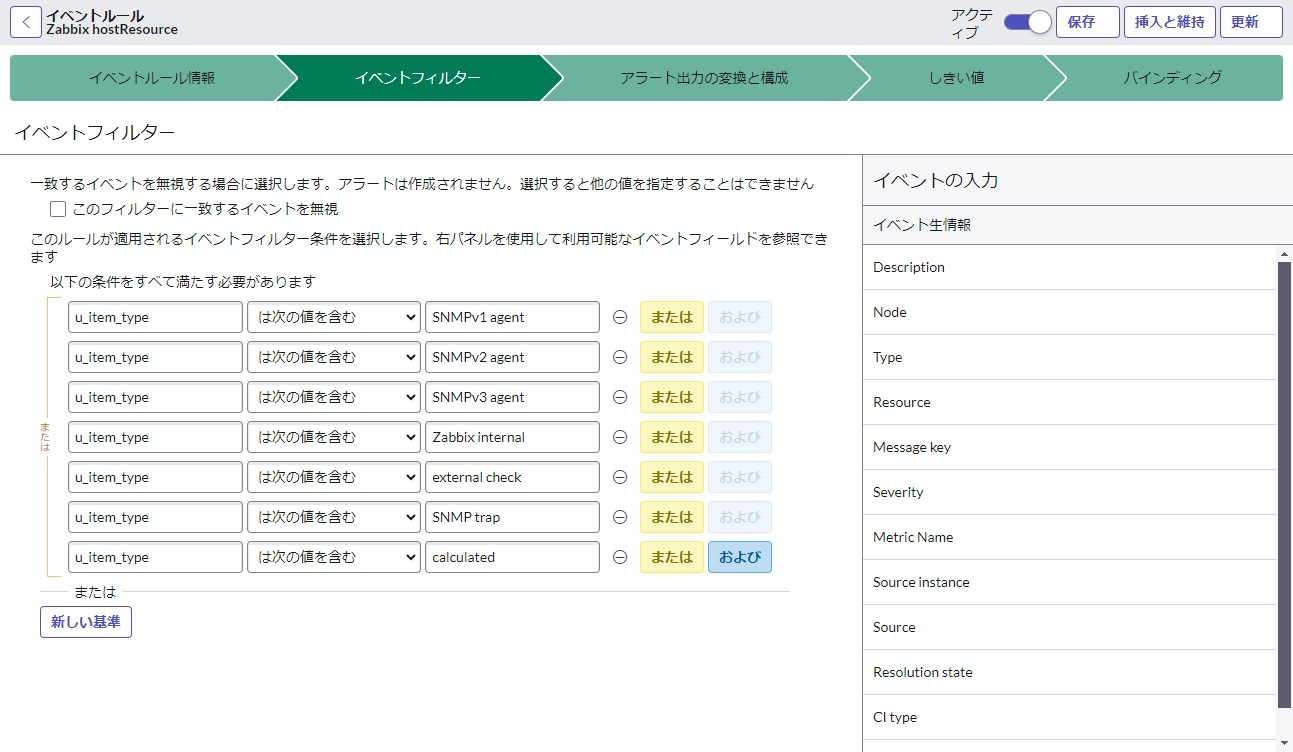
イベントフィルターのタブでは条件を指定する必要があります。外部イベントがこの条件に一致する場合に次のいずれかの処理が実行されます。
アラート出力の変換と構成タブでは、外部イベントの生情報をアラートテーブルの項目へとマッピングします。専用デザイナー内ではドラッグアンドドロップの操作も可能です。
イベントの生情報から正規表現を使って一部キーワードを抜き取ったり、複数項目の値を文字結合したりと、多少の複雑な変換ニーズであっても容易に定義できます。また、[ノード]項目に代入されるホスト名を使ってCIとの引き当てが実施されます。(バインディングタブで変更可能)
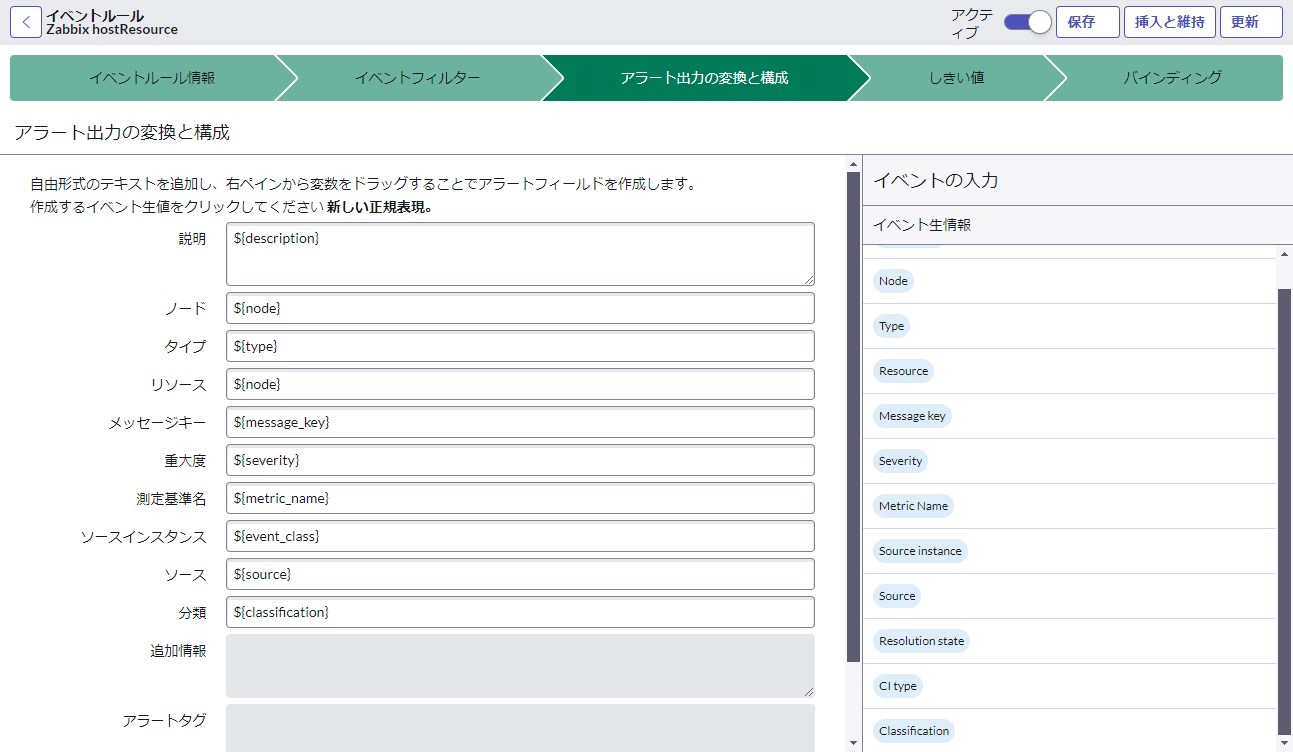
【イベントルール】
イベントルールでは監視ツールから取得したイベントの中からアラートを生成する条件などを事前定義します。受信した外部イベントは Event [em_event]テーブルに保存された後、事前定義されたルールとイベントマッピングに基づいてアラートの生成を試みます。複数のルールが定義されている場合は、順序項目に従って実行されます。[Event Management] > [Rules] > [Event Rules]から新規のイベントルールを作成します。
受信した外部イベントの中に、ルール未定義のものが存在する場合にはインスタンスから自動でルール提案も行われるため、運用開始後にルールを追加する際に役立ちます。
フォーム画面では専用のイベントルールデザイナーでルール定義を編集します。
イベントフィルターのタブでは条件を指定する必要があります。外部イベントがこの条件に一致する場合に次のいずれかの処理が実行されます。
- ・項目のマッピングとCIへのバインディング
- ・該当イベントの無視(アラートを生成しない)
アラート出力の変換と構成タブでは、外部イベントの生情報をアラートテーブルの項目へとマッピングします。専用デザイナー内ではドラッグアンドドロップの操作も可能です。
イベントの生情報から正規表現を使って一部キーワードを抜き取ったり、複数項目の値を文字結合したりと、多少の複雑な変換ニーズであっても容易に定義できます。また、[ノード]項目に代入されるホスト名を使ってCIとの引き当てが実施されます。(バインディングタブで変更可能)
アラート管理ルールの設定
【アラート管理ルール】
アラートが作成されると、定義されたフィルターに従ってアラート管理ルールとの一致を試みます。ルールが一致した場合、プラットフォーム内でさまざまなアクションをトリガーできます。最も一般的な使用例の1つは、アラートに基づいてインシデントを作成することです。[Event Management] > [Rules] > [Alert Management Rules]から新規のアラート管理ルールを作成します。いくつかのアラート管理ルールが予め提供されているため、そのまま正式に採用するか、カスタム時の構築例として確認できます。
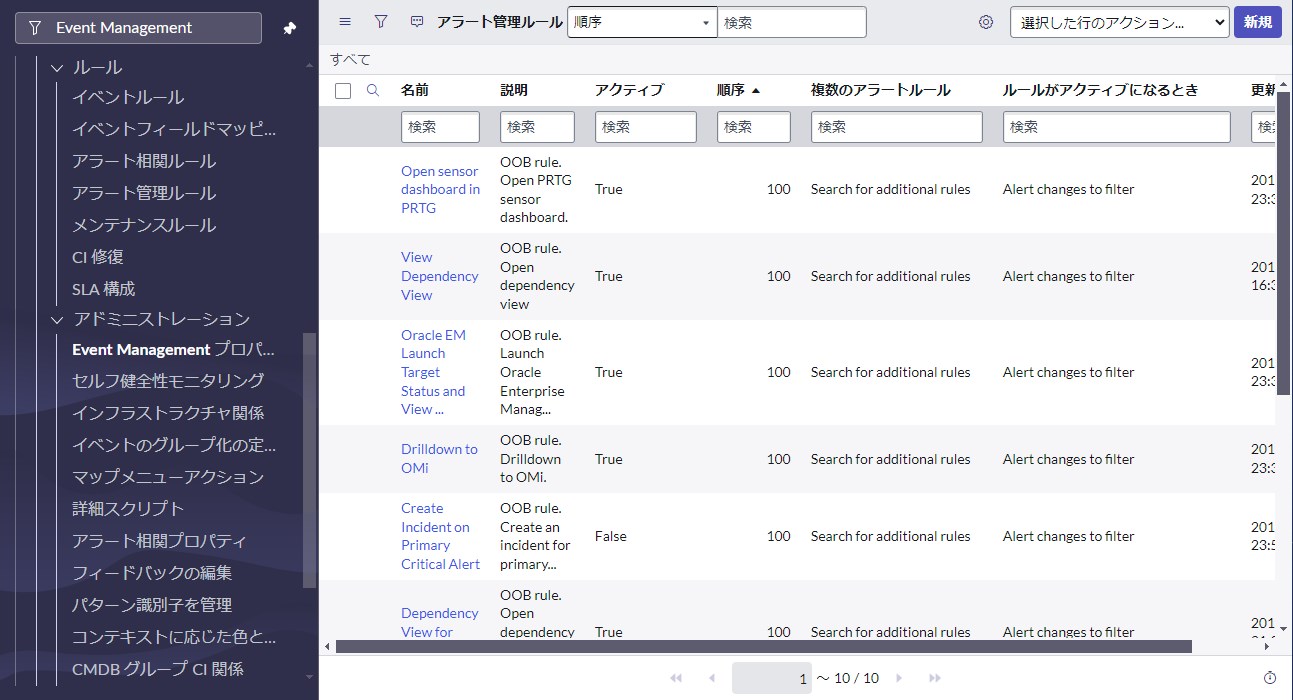
フォーム画面ではProcess Flow Formatterでタブ分割された標準UIでルール定義を編集します。
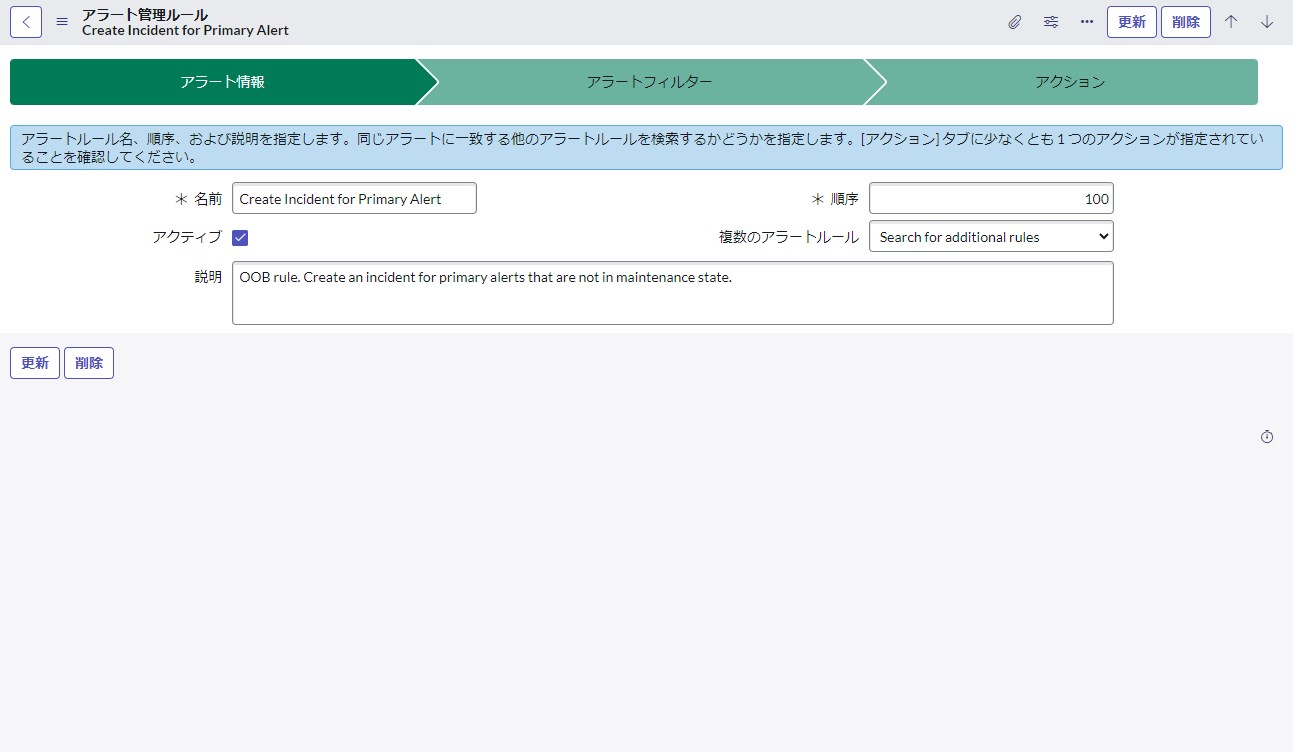
アラートフィルターのタブではフィルターを指定して、ルールが適用されるアラートを決定します。ここでは関連リストの条件を指定できます。指定された条件は、更新されたすべてのオープン状態のアラートに対して、スケジュールジョブによって11秒ごとの周期でチェックされます。
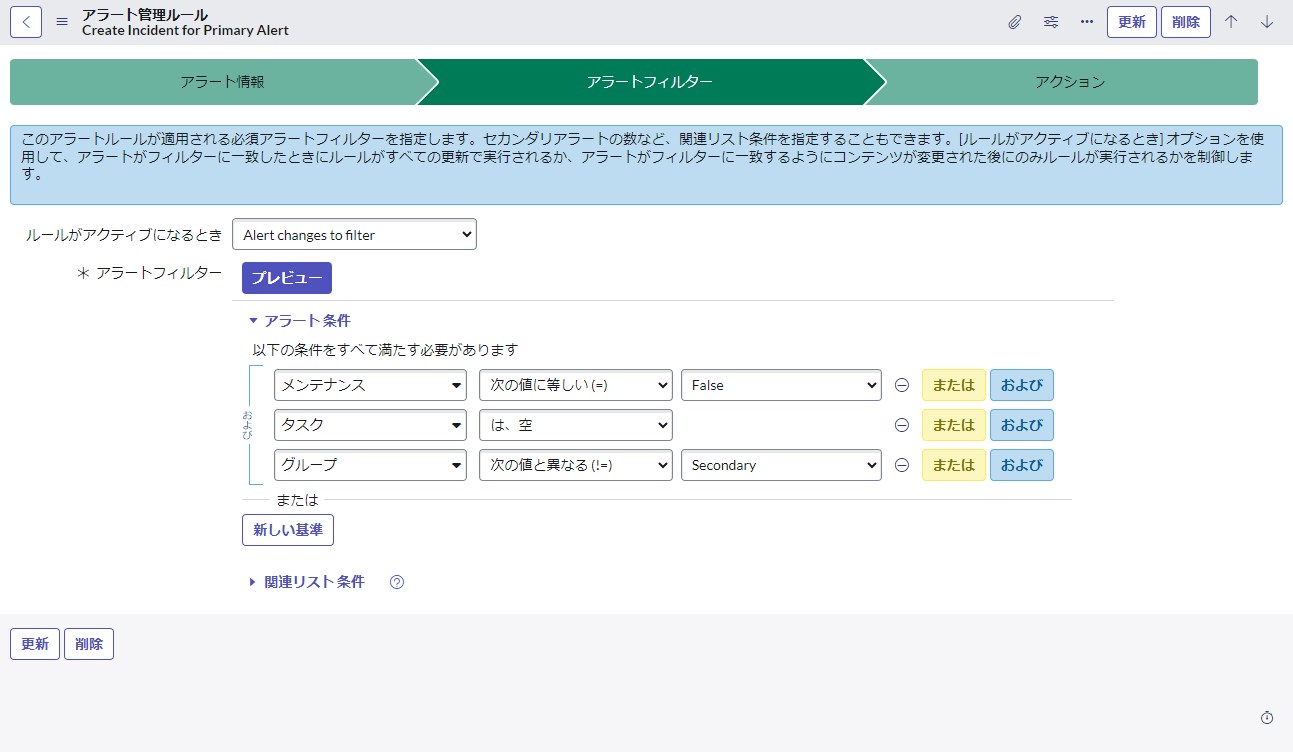
アクションのタブでは、以下のようなアラートへの応答を指定します。
- ・サブフローの実行
- ・修復アクションの実行
- ・アプリケーションの起動
- ・ブラウザでの URL の起動 など
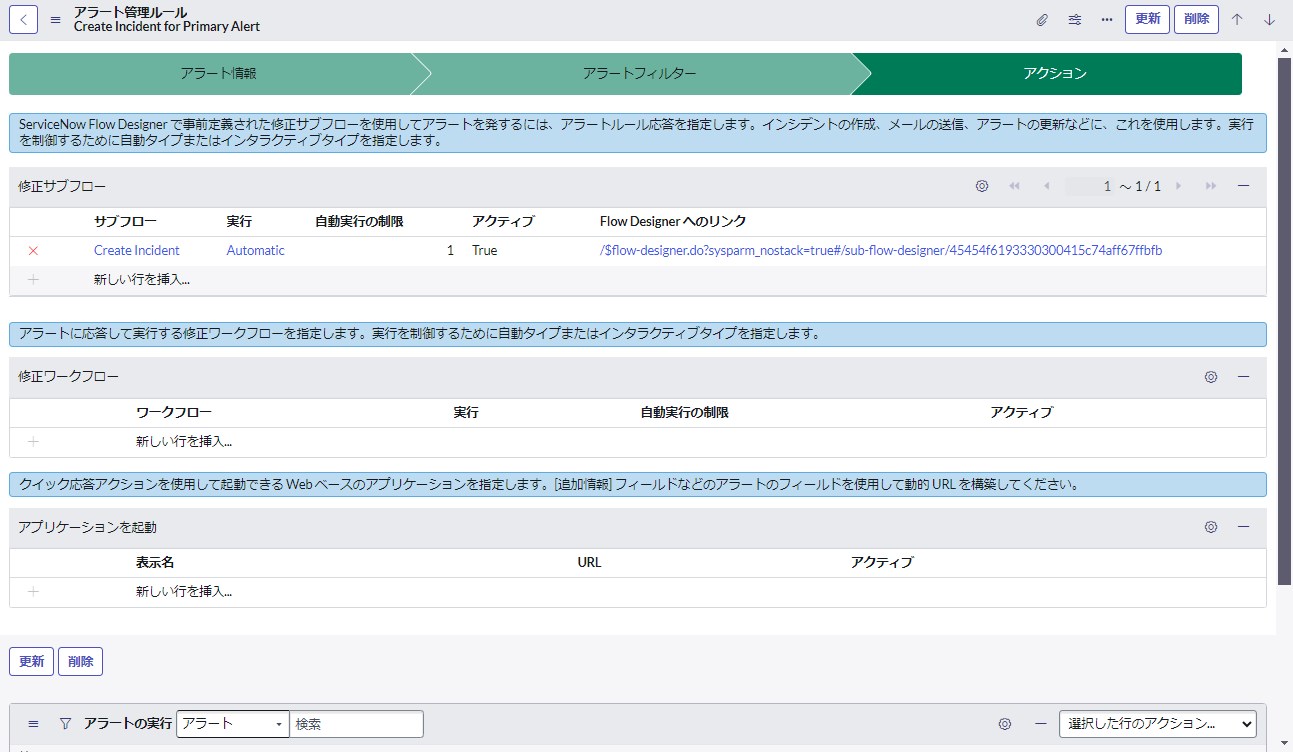
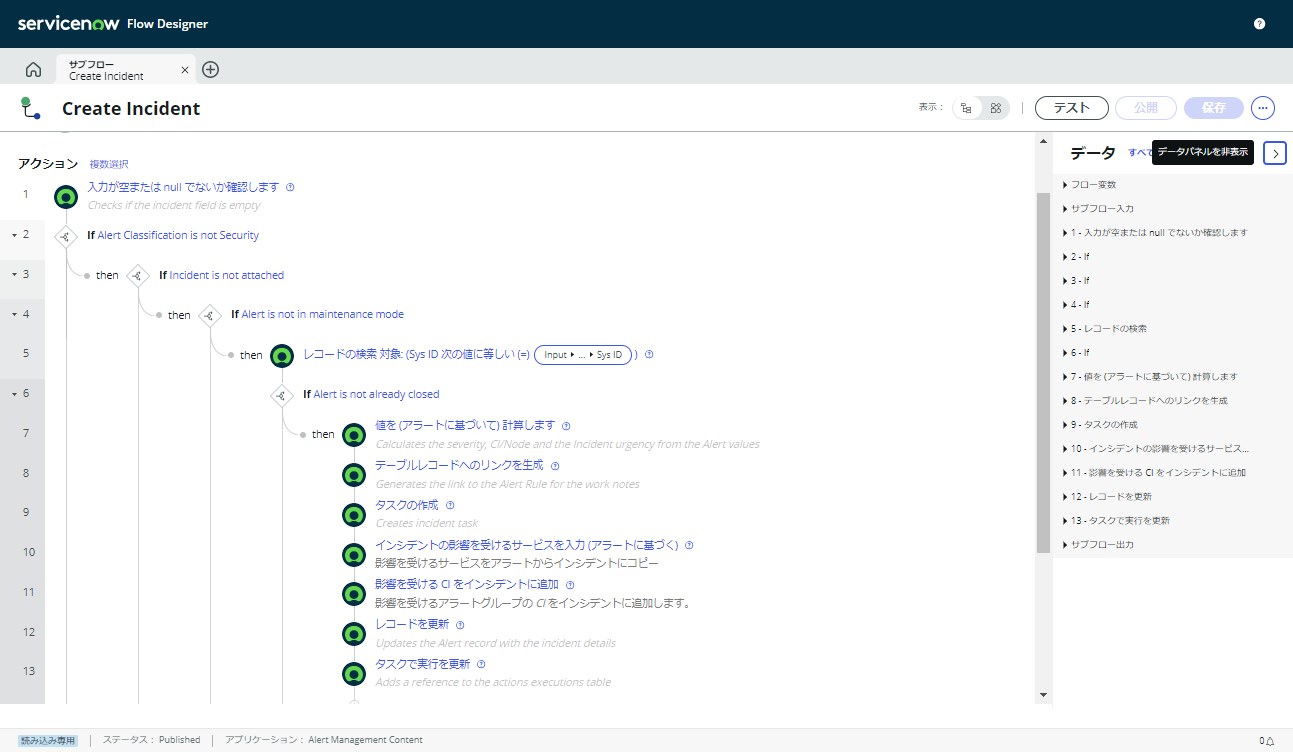
修復サブフローはフローデザイナーを使用して構成されます。アラート情報を元にしてインシデントを作成します。この時点で担当者グループにアサインして対応依頼を通知しておくことでスムーズに対応を開始できます。
簡単な動作イメージ
ここからは簡単な動作イメージをご紹介します。
主な流れとしては以下の通りです。
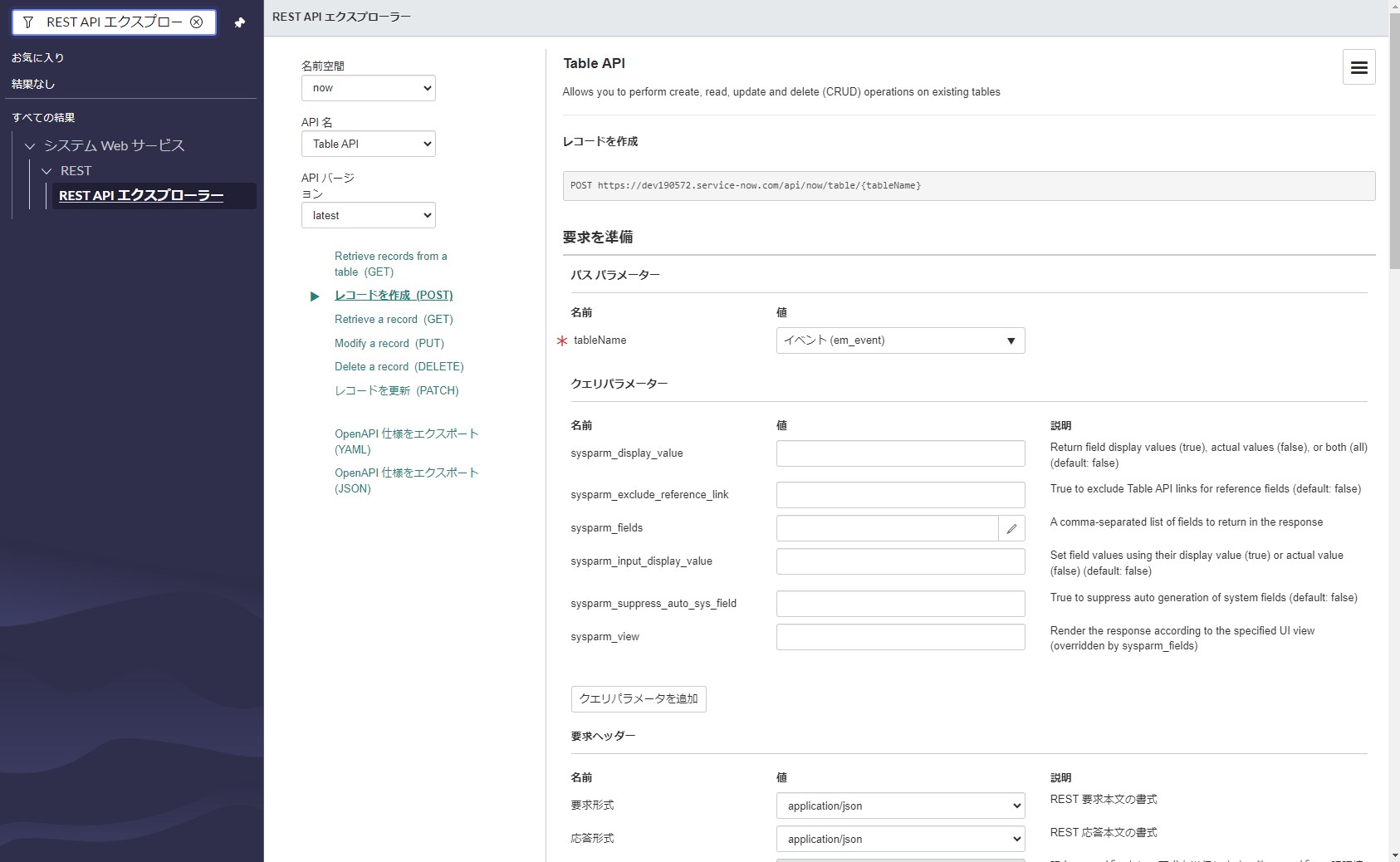
[System Web Services] > [REST] > [REST API Explorer]を開いて、イベントテーブル(em_event)に対してJSONデータを直接流し込みます。同一の日本語テーブル名が存在するため対象を間違えないように注意が必要です。
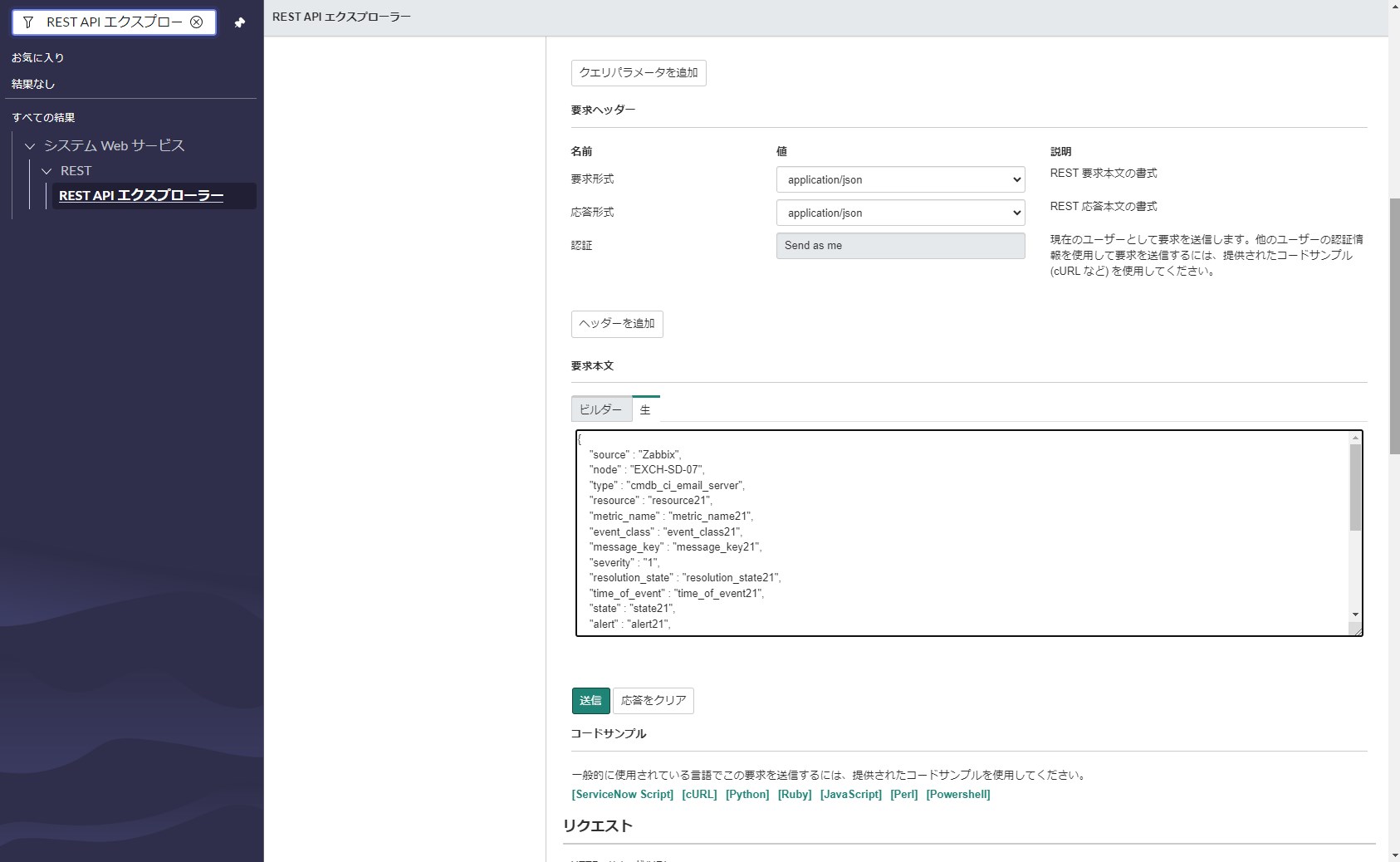
Request Body欄のRawタブにあるテキストエリアにJSONデータを貼り付けて送信します。振り分け結果に大きく関わる項目は、ソース、ノード、重大度です。
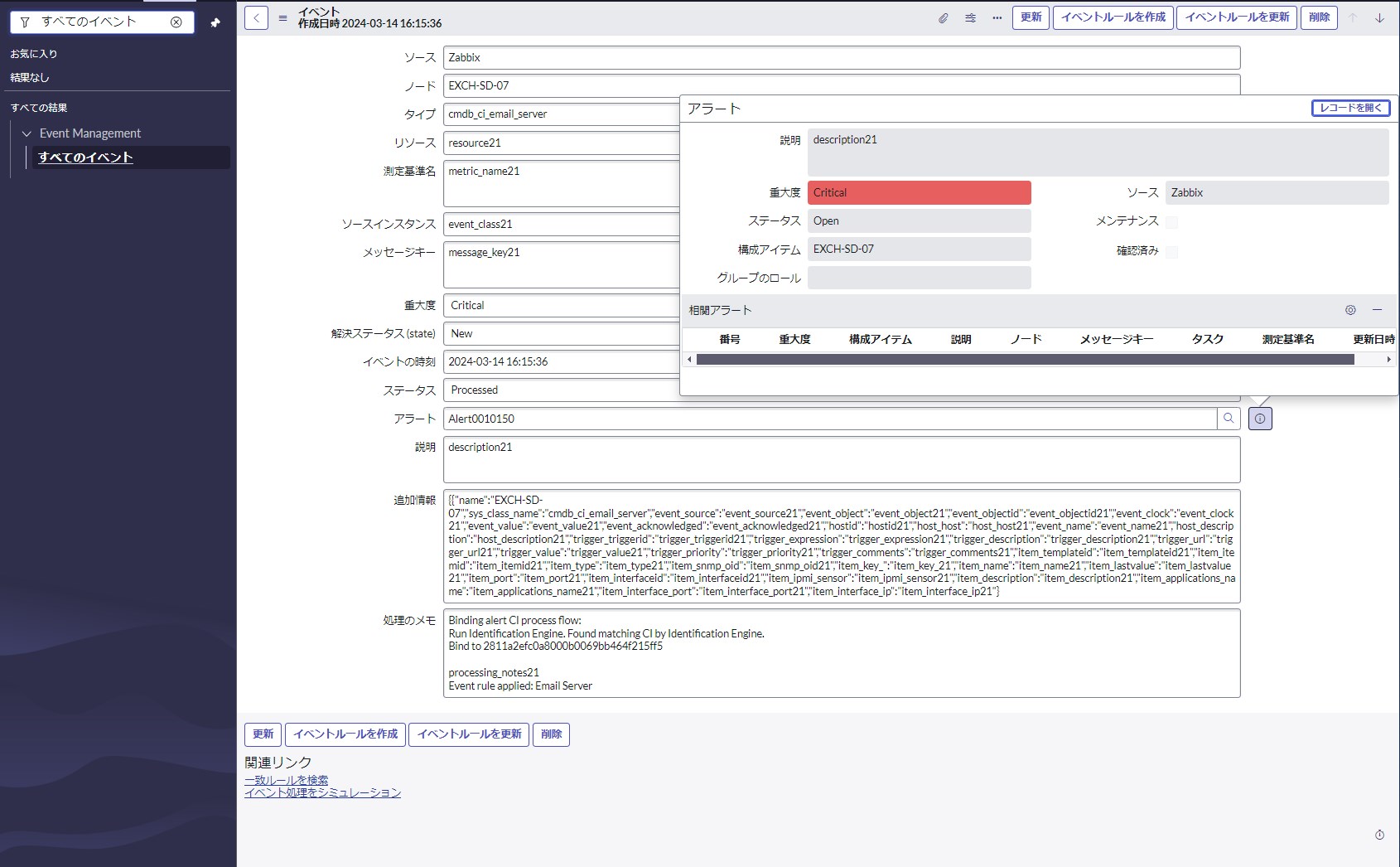
下の画像では既にイベントルールによる一次切り分けが完了しています。[処理のメモ]項目は裏の処理内容が徐々に追記される形式になっており、どのルールが適用されてどのCIと引き当てられたかを後から確認できます。切り分けはイベントを受信して5秒も待たずに完了します。
また、アラートが自動生成されたことも確認できます。もし先に類似したイベント情報を受信していた場合には、生成済みのアラート配下に連なって紐付けされます。
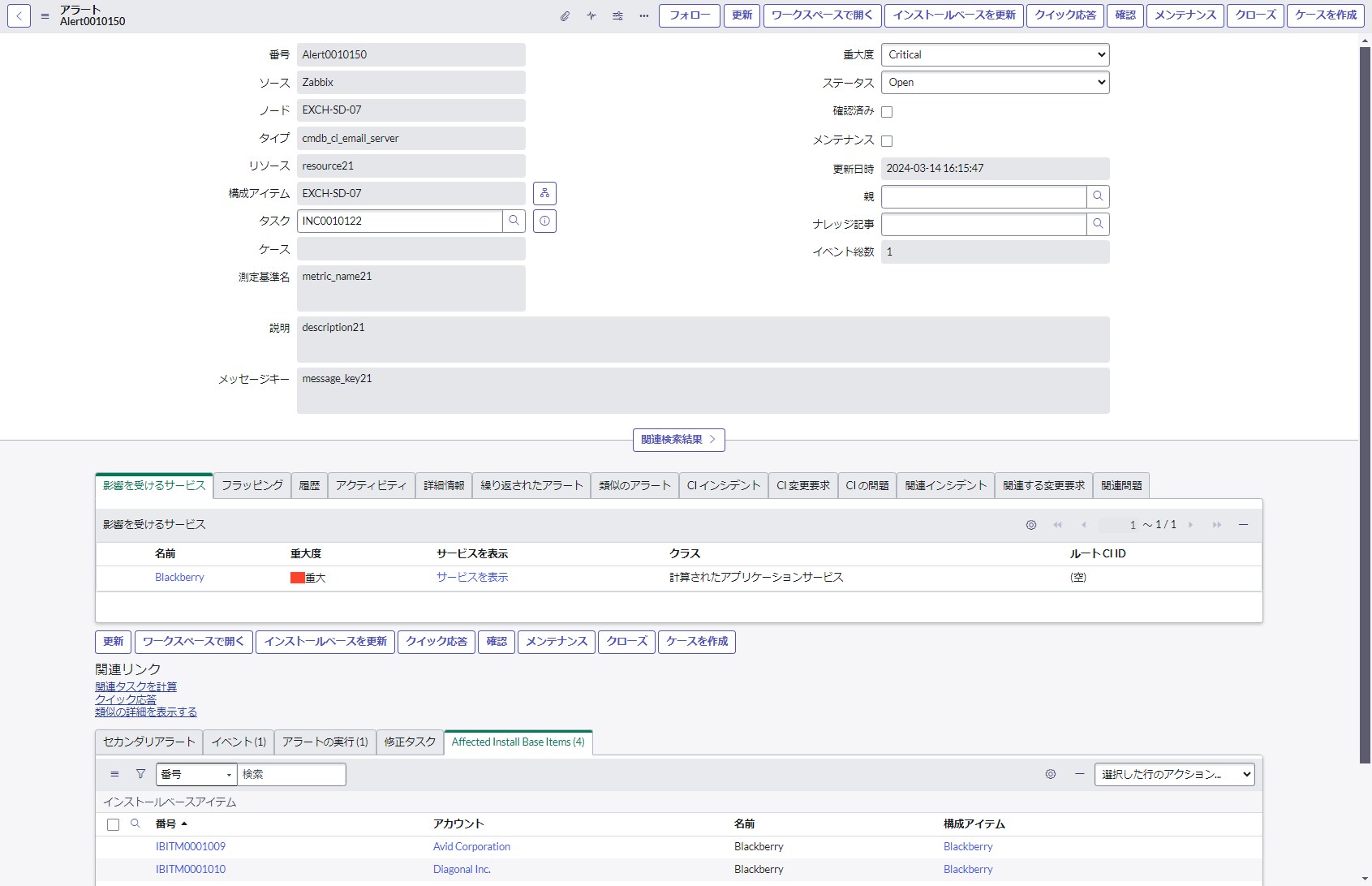
下の画像では既にアラート管理ルールによる修復フローが完了しています。[構成アイテム]項目にCIが設定されており、中段の[影響を受けるサービス]欄には障害によって停止したと思われる影響先サービスが表示されます。(事前にService Mapping情報としてサービスごとのCI構成図を定義しておく必要あり)
また、下段の関連リスト[Affected Install Base Items]では影響を受ける利用者/顧客を直ぐに確認できます。こちらもアラート生成から5秒も待たずに完了します。
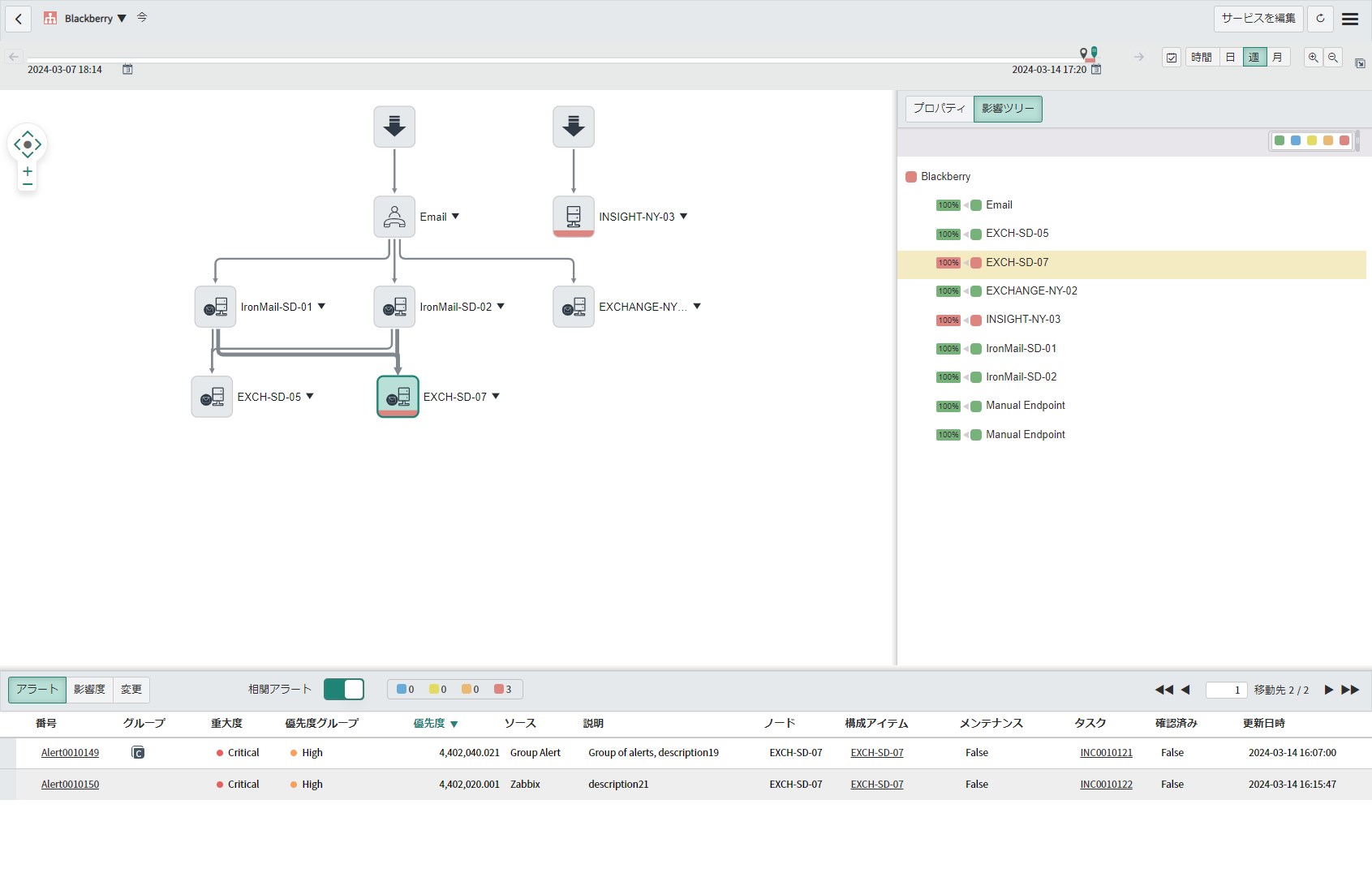
アラート画面の[影響を受けるサービス]タブにある[サービスを表示]というリンクテキストをクリックすると、影響先サービスのマップ(Service Mapping)と影響ツリーの専用ページへ遷移できます。マップ上では停止したCIがサービス内のどこに配置されているかを知ることができます。
以上がデータの流れ/処理の流れに沿ったご説明でした。
最後にもう1つ、併せて押さえておきたい操作メニューに触れておきます。
ダッシュボードアイコン( )をクリックします。
)をクリックします。
サービスダッシュボード画面では組織が提供しているITインフラによるサービスの健康状態を監視できます。アラートにより影響を受けたサービスが発生した場合には、赤く強調表示して異常を知らせます。監視者のニーズに合わせて、表示形式をサービスグループごとや事業上の重要度ごとに切り替えて利用します。
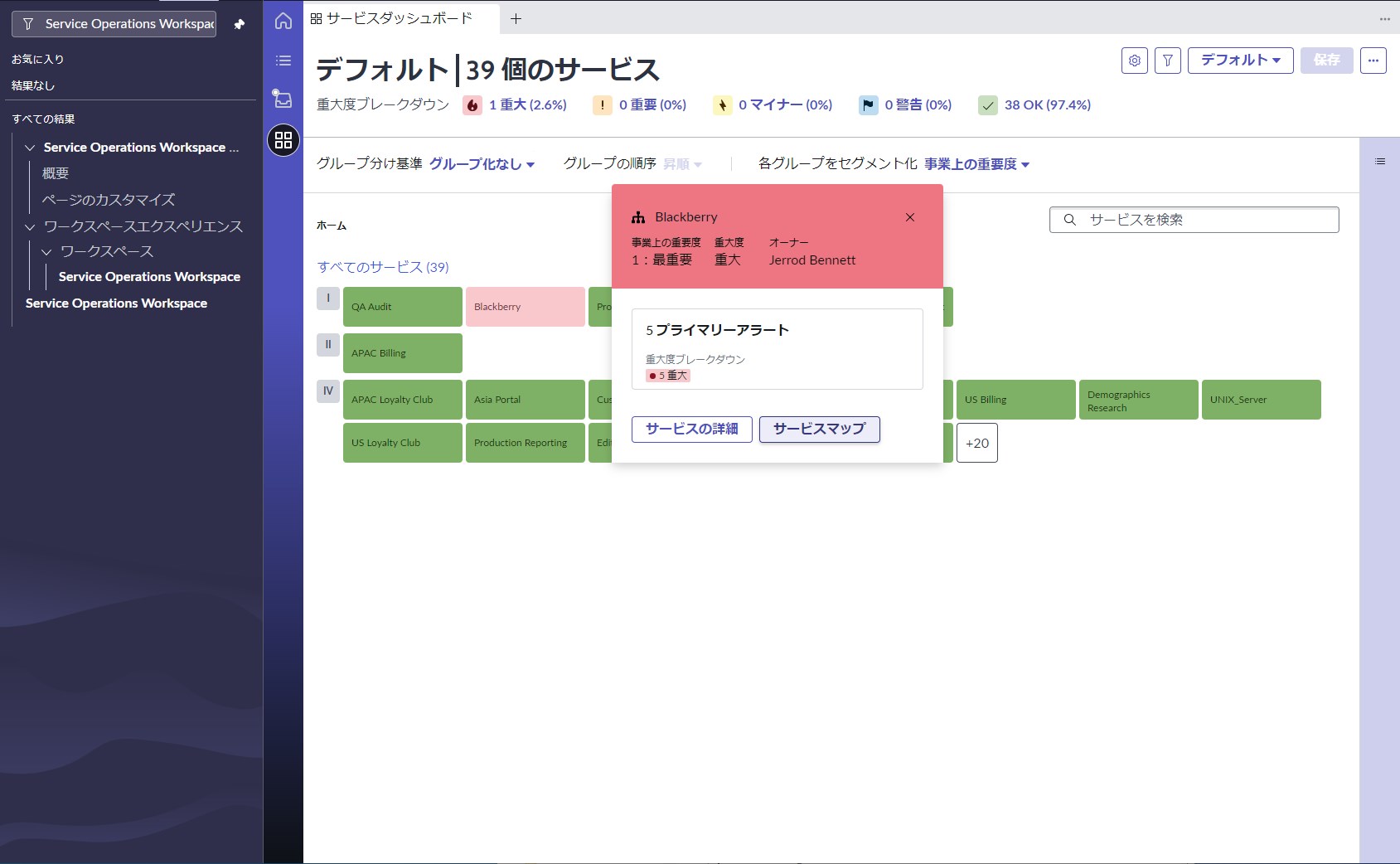
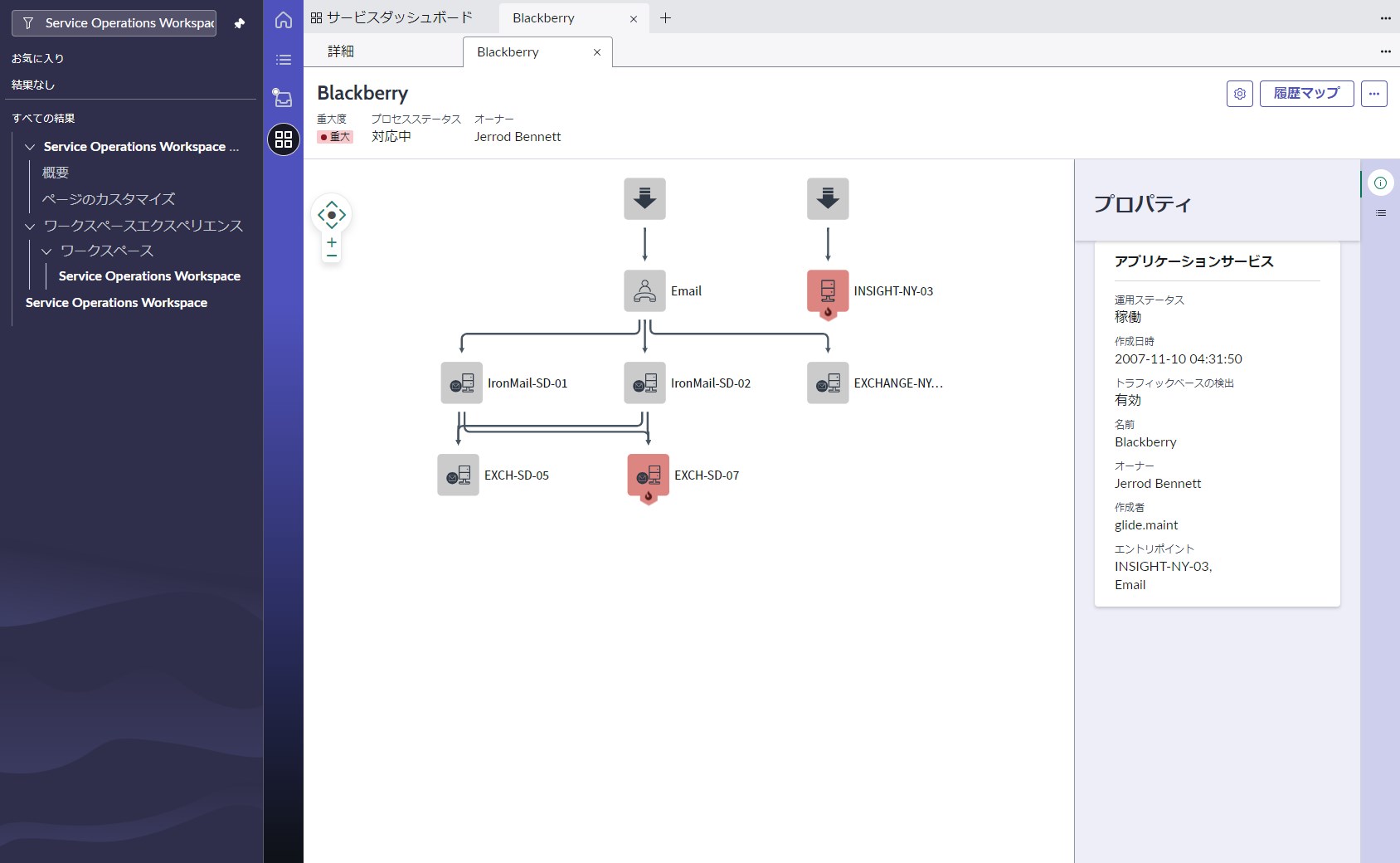
サービスダッシュボード画面でサービスを選択してマップを開くと、サービスからCI、CIからアラートと辿って確認していくことができます。(どのCIに障害があったか/どんなアラートが検出されたか)
さて、今回はイベント管理アプリケーションの導入情報までをご紹介しました。まだまだ奥が深い機能のほんの触り部分でしたが、皆さまが理解を深める足掛かりになれば幸いです。
今後もServiceNowが持つ機能やその活用方法、実践的な導入ノウハウやカスタマイズ方法など、幅広い内容を発信していきたいと思います。
ServiceNowの高度な実装には、弊社のServiceNow導入サービスをよろしくお願いいたします。ServiceNowについて更に詳しく知りたい方は、ServiceNowに熟知したSTSメンバーがよりよいシステム構築をご提案しますので、ぜひご相談ください。
主な流れとしては以下の通りです。
- 外部イベントの受信:
今回はREST APIエクスプローラーから外部データを模して送信します。生のイベントデータとして記録されます。 - アラートの自動生成:
イベントルール条件に一致してアラートが生成されます。ここでCIが引き当てられることによって、さまざまな影響情報を取得できます。 - インシデントの自動生成:
アラート管理ルール条件に一致してインシデントが生成されます。エラー内容や影響情報を元にして対応します。
[System Web Services] > [REST] > [REST API Explorer]を開いて、イベントテーブル(em_event)に対してJSONデータを直接流し込みます。同一の日本語テーブル名が存在するため対象を間違えないように注意が必要です。
Request Body欄のRawタブにあるテキストエリアにJSONデータを貼り付けて送信します。振り分け結果に大きく関わる項目は、ソース、ノード、重大度です。
【イベントルールの動作結果】
イベントデータが生成されましたので、[Event Management] > [All Events]から確認します。あくまでも内部データであるため、イベントから辿る動線は業務管理者向けです。多くの担当者は後述のサービスダッシュボード上で事象を検知するか、インシデントから発報される要対応通知が運用上のトリガーとなります。下の画像では既にイベントルールによる一次切り分けが完了しています。[処理のメモ]項目は裏の処理内容が徐々に追記される形式になっており、どのルールが適用されてどのCIと引き当てられたかを後から確認できます。切り分けはイベントを受信して5秒も待たずに完了します。
また、アラートが自動生成されたことも確認できます。もし先に類似したイベント情報を受信していた場合には、生成済みのアラート配下に連なって紐付けされます。
【アラート管理ルールの動作結果】
つづいて自動生成されたアラートデータを確認します。下の画像では既にアラート管理ルールによる修復フローが完了しています。[構成アイテム]項目にCIが設定されており、中段の[影響を受けるサービス]欄には障害によって停止したと思われる影響先サービスが表示されます。(事前にService Mapping情報としてサービスごとのCI構成図を定義しておく必要あり)
また、下段の関連リスト[Affected Install Base Items]では影響を受ける利用者/顧客を直ぐに確認できます。こちらもアラート生成から5秒も待たずに完了します。
アラート画面の[影響を受けるサービス]タブにある[サービスを表示]というリンクテキストをクリックすると、影響先サービスのマップ(Service Mapping)と影響ツリーの専用ページへ遷移できます。マップ上では停止したCIがサービス内のどこに配置されているかを知ることができます。
以上がデータの流れ/処理の流れに沿ったご説明でした。
最後にもう1つ、併せて押さえておきたい操作メニューに触れておきます。
【サービスダッシュボード】
[Workspace Experience] > [Workspaces] > [Service Operations Workspace]を開きます。なお、この[Service Operations Workspace]自体が運用者向けUIであり、複数タブで関連レコードを並べて業務を行うのに適しています。ダッシュボードアイコン(
サービスダッシュボード画面では組織が提供しているITインフラによるサービスの健康状態を監視できます。アラートにより影響を受けたサービスが発生した場合には、赤く強調表示して異常を知らせます。監視者のニーズに合わせて、表示形式をサービスグループごとや事業上の重要度ごとに切り替えて利用します。
サービスダッシュボード画面でサービスを選択してマップを開くと、サービスからCI、CIからアラートと辿って確認していくことができます。(どのCIに障害があったか/どんなアラートが検出されたか)
さて、今回はイベント管理アプリケーションの導入情報までをご紹介しました。まだまだ奥が深い機能のほんの触り部分でしたが、皆さまが理解を深める足掛かりになれば幸いです。
今後もServiceNowが持つ機能やその活用方法、実践的な導入ノウハウやカスタマイズ方法など、幅広い内容を発信していきたいと思います。
ServiceNowの高度な実装には、弊社のServiceNow導入サービスをよろしくお願いいたします。ServiceNowについて更に詳しく知りたい方は、ServiceNowに熟知したSTSメンバーがよりよいシステム構築をご提案しますので、ぜひご相談ください。

