2023年6月1日
【Google Cloud】Datastream for BigQueryを使ってみた!
-

- Category Google Cloud
-

- author みやてつ

Google CloudのDatastream for BigQueryが2023年4月に一般提供(GA)になりました。
Datastream for BigQueryは、OracleやPostgreSQL、MySQLのトランザクションデータをリアルタイムにBigQueryにレプリケーション(複製)するサービスです。
このサービスを使うことで、リアルタイムに更新され続けるデータを用いて、BigQuery上でデータ分析を行うことができます。
今回は、PostgreSQLを使ってDatastream for BigQueryを試してみました。
Datastream for BigQueryについて
転送元となるデータベースについて
2023年4月時点で、次のデータベースに対応しています。
オンプレ環境のデータベースやCloud SQL、AlloyDB、Amazon RDS、Amazon Auroraなどのフルマネージドのデータベースに対応しています。
| データベース | バージョンなど(2023/4時点) |
| Oracle | Oracle 11g (11.2.0.4), Oracle 12c (12.1.0.2, 12.2.0.1 ), Oracle 18c, 19c, 21c |
| PostgreSQL | PostgreSQL 10以降 |
| MySQL | MySQL 5.6, MySQL 5.7, MySQL 8.0 |
データ取得は、Datastreamからデータベースに接続します。また、データベースのレプリケーション機能を使用します。そのため、導入時にデータベースの設定を変更したり、ユーザーを作成したりなど、データベースの管理権限が必要となります。
詳細は、以下のページに記載されています。
https://cloud.google.com/datastream/docs/sources
データベースへの接続について
データ取得を行うために、Datastreamからデータベースに接続します。
データベースへの接続方法は、次の3種類がサポートされています。
| 方法 | 内容 |
| IP許可リスト | 特定のパブリックIPアドレスからデータベースへの接続を許可して、接続します。 |
| フォワードSSHトンネル | SSHを使用して踏み台サーバに接続し、データベースに接続します。 |
| VPCピアリング | データベースとGoogle Cloudの間にプライベートネットワークを構築して接続します。 |
詳細は、以下のページに記載されています。
https://cloud.google.com/datastream/docs/network-connectivity-options
料金について
料金は、データ更新方法により次の2種類があります。
| 種類 | 内容 |
| Change data capture (CDC) | ストリーミングを使用してリアルタイムにデータを更新するときの料金 |
| Backfill | テーブル全体のスナップショットを取得して更新するときの料金 |
Change data capture (CDC)の料金は、転送するデータ量でGB単位で課金されます。
データ量に応じて、段階的にGB単位の単価が安くなります。
Backfillの料金は、毎月500GBまで無料です。500GBを超えた場合は、GB単位で定額料金で課金されます。
詳細は、以下のページに記載されています。
https://cloud.google.com/datastream/pricing
また、上記のDatastreamの料金以外にもデータの転送、保存、処理を行うため、BigQueyやネットワークなどの料金が発生します。
PostgreSQLを使用したDatastream for BigQueryの構築
今回は、オンプレ環境のPostgreSQLを想定してDatastream for BigQueryを試してみます。
PostgreSQLは、GCE(Google Compute Engine)にインストールしました。
OSは、Debian GNU/Linux 11 (bullseye)、PostgreSQLのバージョンは、13.9です。
Datastream for BigQueryからPostgreSQLへの接続方法は、IP許可リストを使用します。
ストリーム転送されるデータには制限事項があります。PostgreSQLを使用した場合は、以下のページに記載されいます。
https://cloud.google.com/datastream/docs/sources-postgresql#postgresqlknownlimitations
データベース設定(Self-managed PostgreSQL)
転送元のデータベースの設定を行います。
設定方法は、データベースの種類やタイプ(Self-managedやCloud SQLなど)毎にドキュメントに記載されています。
今回は、Self-managed PostgreSQL用のドキュメントを参照して設定します。
https://cloud.google.com/datastream/docs/configure-your-source-postgresql-database#selfhostedpostgresql
1.データベースのレプリケーション機能を有効にします。
PostgreSQLの場合は、PostgreSQLの機能であるロジカルレプリケーションを使用します。
※送信元のデータベースによって利用する機能が異なります。
PostgreSQLのロジカルレプリケーションは、データの更新履歴であるWAL(Write Ahead Log)を論理デコードしてレプリケーション先に転送する機能です。転送は、コミットのタイミングで行われ、送信元をパブリッシャー、送信先をサブスクライバーと呼びます。通常はサブスクライバーも同じPostgreSQLになりますが、Datastreamがサブスクライバーとなってデータを受信するようです。
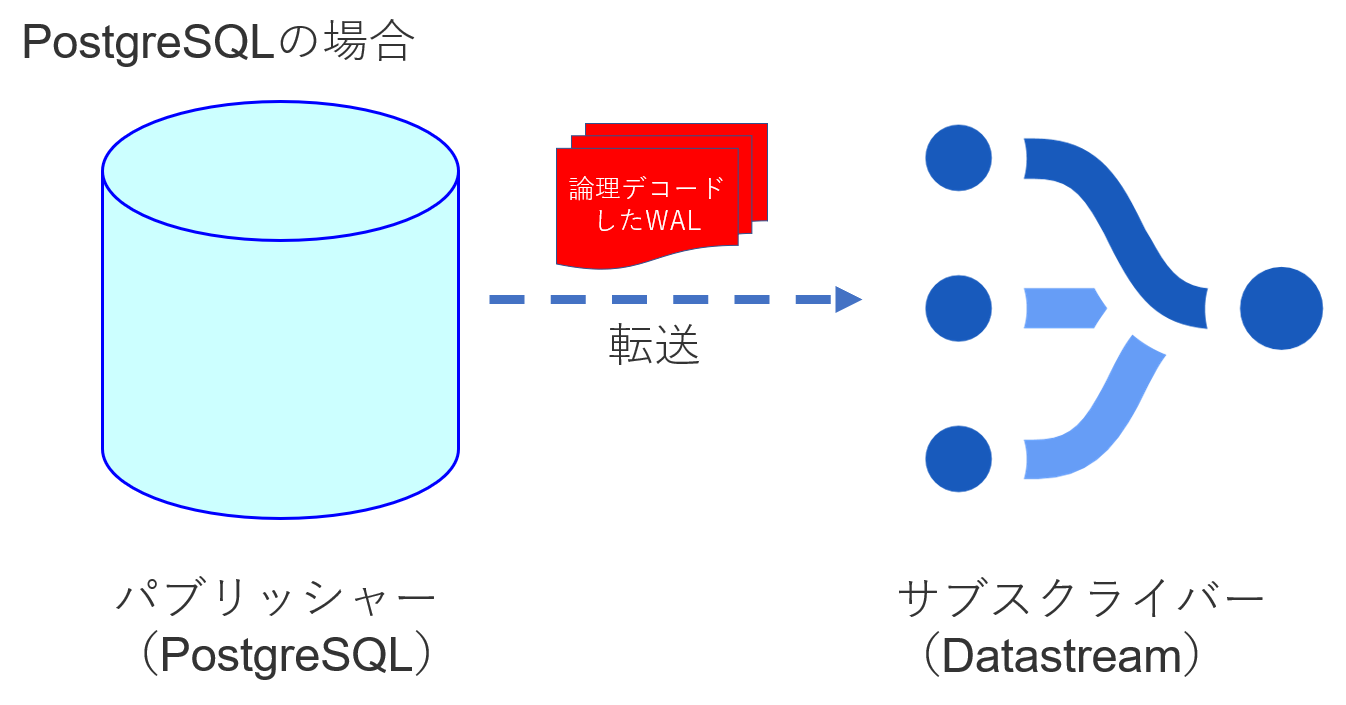
[手順1]PostgreSQLの設定ファイルを変更します。
”wal_level”を有効にして、”logical”に設定します。
/etc/postgresql/13/main/postgresql.conf ※設定ファイルの場所はインストール方法によって異なります。
#------------------------------------------------------------------------------
# WRITE-AHEAD LOG
#------------------------------------------------------------------------------
# - Settings -
wal_level = logical # minimal, replica, or logical
# (change requires restart)
[手順2]PostgreSQLのサービスを再起動します。
2.レプリケートするテーブルのパブリケーションを作成します。
[手順1]psqlでデータベースにログインします。
[手順2]SQLでパブリケーションを作成します。
#全てのテーブルを対象とする場合
CREATE PUBLICATION [PUBLICATION_NAME] FOR ALL TABLES;
#指定したテーブルを対象とする場合
CREATE PUBLICATION [PUBLICATION_NAME]
FOR TABLE [SCHEMA1.TABLE1], [SCHEMA2.TABLE2], ・・・;
※[PUBLICATION_NAME]は任意の名称に書き換えてください。小文字です。
今回は全てのテーブルを対象とし「publication_all_tables」という名称で作成しました。
CREATE PUBLICATION publication_all_tables FOR ALL TABLES;
3.レプリケーションスロットを作成します。
[手順1]SQLでレプリケーションスロットを作成します。
SELECT PG_CREATE_LOGICAL_REPLICATION_SLOT('[REPLICATION_SLOT_NAME]', 'pgoutput');
※[REPLICATION_SLOT_NAME]は任意の名称に書き換えてください。小文字です。
今回は「replication_slot_mydb」というレプリケーションスロットを作成しました。
SELECT PG_CREATE_LOGICAL_REPLICATION_SLOT('replication_slot_mydb', 'pgoutput');
4.Datastreamから接続するユーザーを作成します。
[手順1]SQLでユーザーを作成します。
CREATE USER [USER_NAME] WITH ENCRYPTED PASSWORD '[USER_PASSWORD]';
※[USER_NAME]や[USER_PASSWORD]は任意で書き換えてください。USER_NAMEは小文字です。
今回は「bq_replication_user」というユーザーを作成しました。
CREATE USER bq_replication_user WITH ENCRYPTED PASSWORD 'XXXXXXXXXXXX';
[手順2]SQLでユーザーに対して権限を設定します。
# レプリケーション権限を付与 ALTER ROLE [USER_NAME] WITH REPLICATION; # 既存のテーブルに対してSELECT権限を付与 GRANT SELECT ON ALL TABLES IN SCHEMA [SCHEMA_NAME] TO [USER_NAME]; # 使用権限を付与 GRANT USAGE ON SCHEMA [SCHEMA_NAME] TO [USER_NAME]; # デフォルトでSELECT権限を付与 ALTER DEFAULT PRIVILEGES IN SCHEMA [SCHEMA_NAME] GRANT SELECT ON TABLES TO [USER_NAME];
※[USER_NAME]や[SCHEMA_NAME]は任意で書き換えてください。
今回は以下のSQLを実行しました。
ALTER ROLE bq_replication_user WITH REPLICATION; GRANT SELECT ON ALL TABLES IN SCHEMA public TO bq_replication_user; GRANT USAGE ON SCHEMA public TO bq_replication_user; ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT ON TABLES TO bq_replication_user;
5.DatastreamのIPからの接続を許可します。(IP許可リストによる接続)
[手順1]PostgreSQLのクライアント認証の設定ファイルに追記します。
/etc/postgresql/13/main/pg_hba.conf ※設定ファイルの場所はインストール方法によって異なります。
# TYPE DATABASE USER ADDRESS METHOD host mydb bq_replication_user 34.146.175.7/32 md5 host mydb bq_replication_user 34.146.177.122/32 md5 host mydb bq_replication_user 35.194.107.163/32 md5 host mydb bq_replication_user 35.189.147.253/32 md5 host mydb bq_replication_user 34.84.33.5/32 md5
USERは、「4.Datastreamから接続するユーザーを作成します。」で作成したユーザーを指定してください。
ADDRESSのアドレスは、リージョン毎にドキュメントに記載されています。
今回は、asia-northeast1(東京)のIPを追記しています。
https://cloud.google.com/datastream/docs/ip-allowlists-and-regions
その他に本記事では触れませんが、外部から接続できるようにファイアウォールの設定が必要です。
[手順2]PostgreSQLのサービスを再起動します。
6.その他(任意の設定)
ドキュメントに、WALログに関するおすすめ設定が記載されています。
必要に応じて設定するとよいと思います。今回はスキップしました。
https://cloud.google.com/datastream/docs/work-with-postgresql-database-wal-log-files
Datastream for BigQueryの構築
1.Datastreamにアクセスします。
[手順1] Google CloudのコンソールでDatastreamを検索してアクセスします。
[手順2] Datastream APIを有効にします。
2.ストリームの作成を行います。
[手順1] 「ストリームの作成」ボタンを押します。
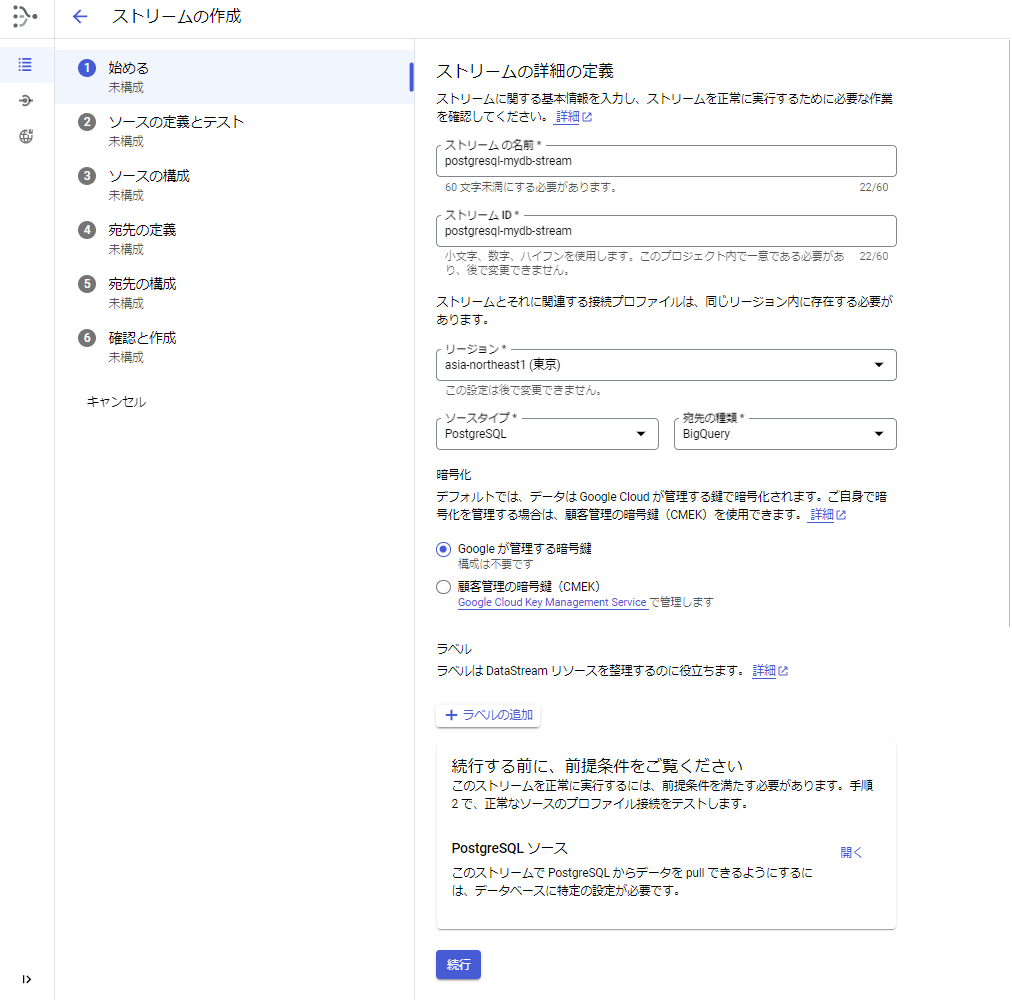
[手順2] 「①始める」を入力します。
1.ストリームの名前、ストリームIDを入力します。
2.リージョンを選択します。
3.ソースタイプで「PostgreSQL」を選択します。
4.宛先の種類で「BigQuery」を選択します。
5.そのほかの項目はデフォルトのままです。
6.「続行」ボタンを押します。
[手順3] 「②ソースの定義とテスト」の接続設定の定義を入力します。
1.接続プロファイルの名前を入力します。
2.接続の詳細(ホスト名(IPアドレス)、ポート番号、ユーザー名、パスワード、データベース名)を入力します。
※PostgreSQLに対する接続情報を入力します。
※今回は、ホスト名(IPアドレス)にはGCEインスタンスの外部IPを入力しました。
3.「続行」ボタンを押します。
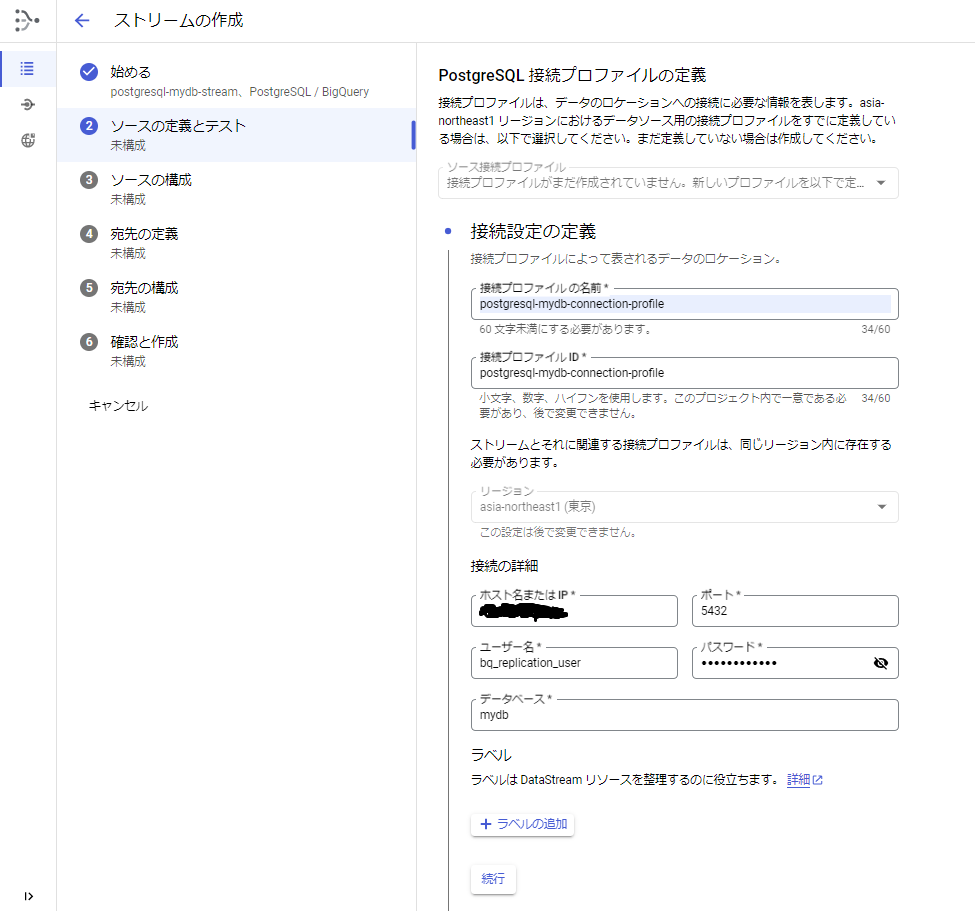
[手順4] 「②ソースの定義とテスト」の接続方法の定義を入力します。
1.接続方法で「IP許可リスト」を選択します。
選択すると選択したリージョンのIPが表示されます。※ドキュメントに記載されているIPと同じでした。
2.「続行」ボタンを押します。
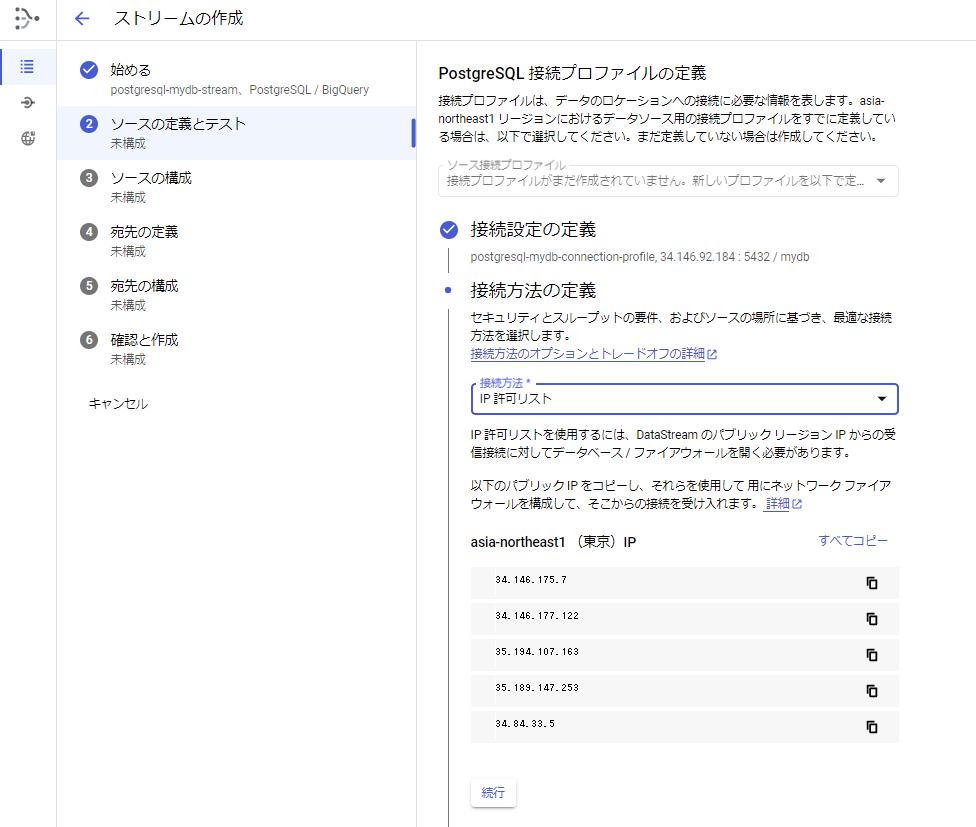
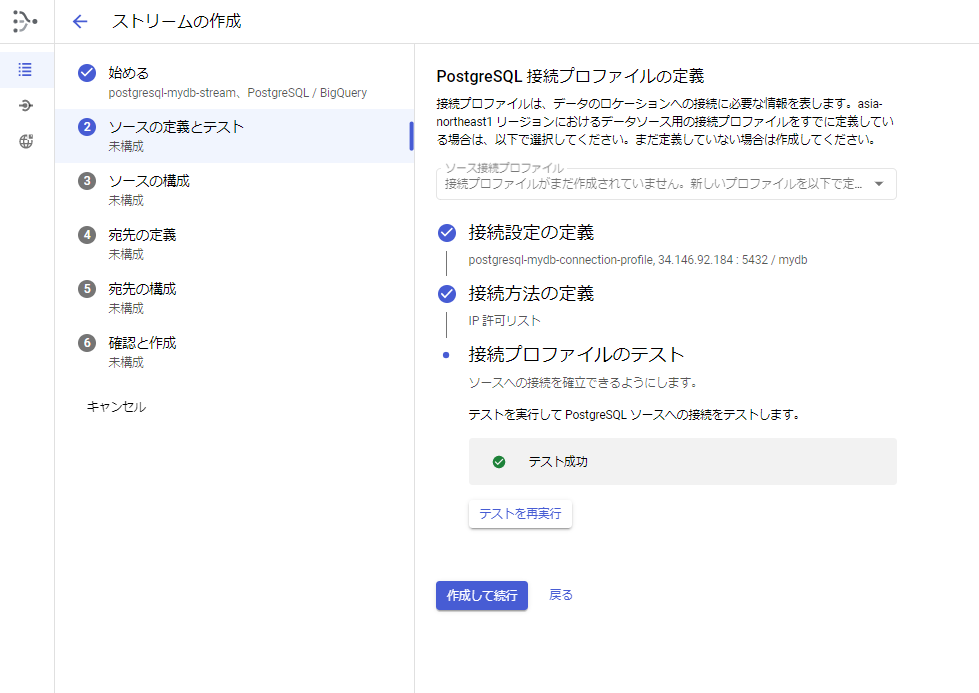
[手順5] 「②ソースの定義とテスト」の接続プロファイルのテストを行います。
1.接続プロファイルのテストを行います。
2.「作成して続行」ボタンを押します。
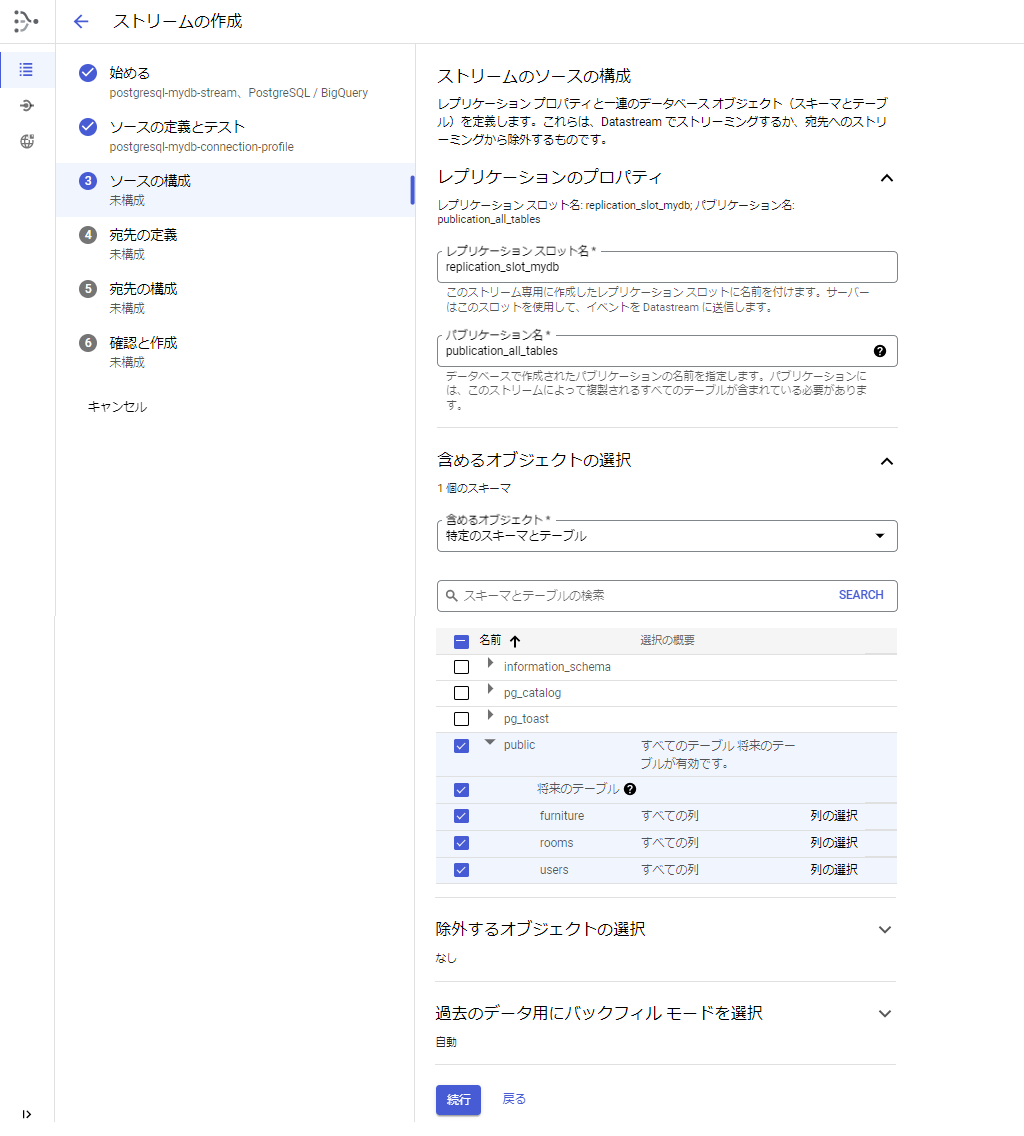
[手順6] 「③ソースの構成」を入力します。
1.レプリケーションスロット名を入力します(PostgreSQLで設定した名前を入力します)。
例:replication_slot_mydb
2.パブリケーション名を入力します(PostgreSQLで設定した名前を入力します)。
例:publication_all_tables
3.含めるオブジェクトの選択で、ストリーミングするスキーマやテーブルを選択します。
4.「続行」ボタンを押します。
[手順7] 「④宛先の定義」を入力します。
1.接続プロファイルの名前を入力します。
2.そのほかの項目はデフォルトのままです。
3.「作成して続行」ボタンを押します。
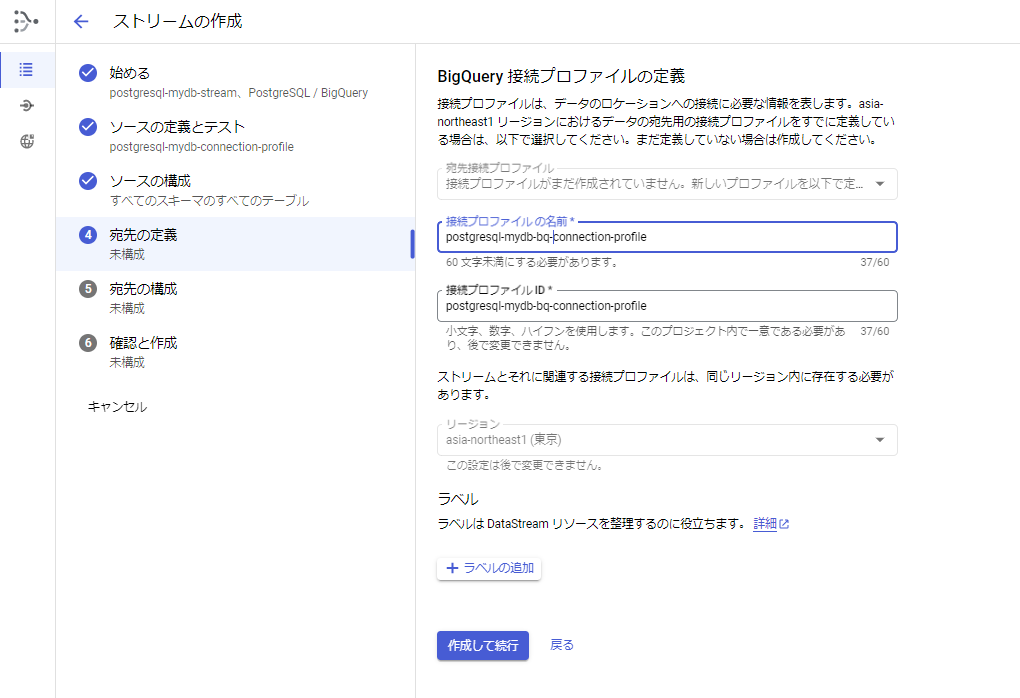
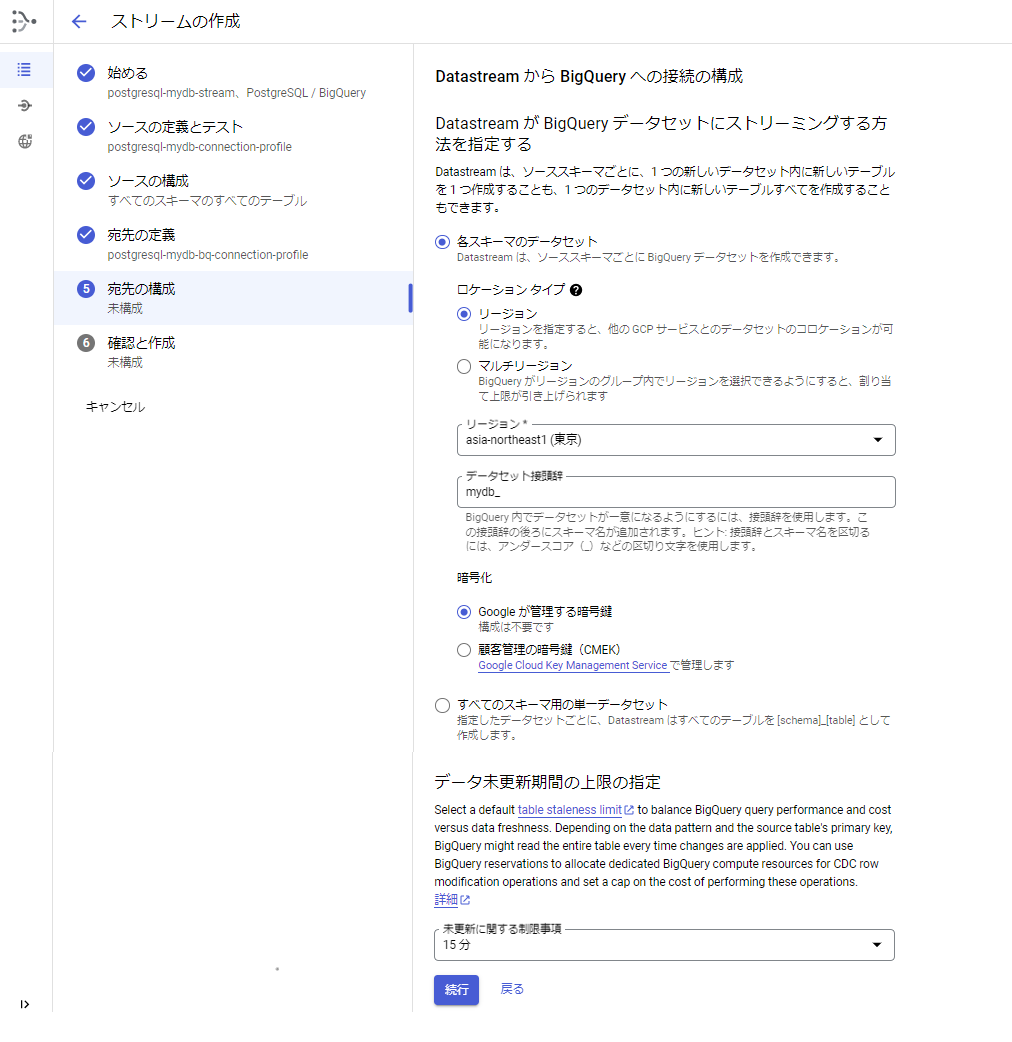
[手順8] 「⑤宛先の構成」を入力します。
1.「各スキーマのデータセット」を選択します。
※データベースのスキーマ毎にBigQueryのデータセットが作成されます。
2.リージョン、データセットの接頭辞を入力します。
3.データ未更新上限の指定を選択します(デフォルトは15分です)。
4.「続行」ボタンを押します。
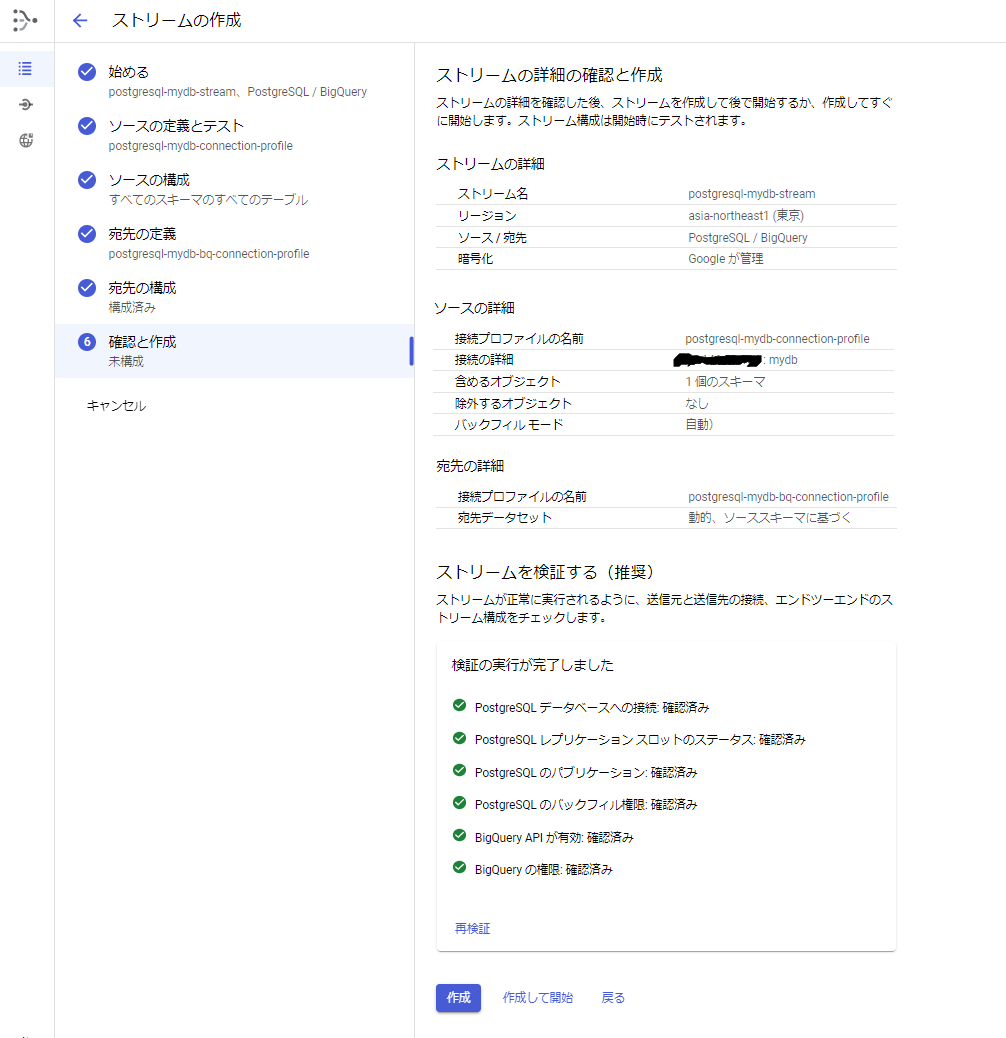
[手順9] 「⑥確認と作成」で設定内容を確認します。
1.画面の設定内容を確認します。
2.ストリームを検証します。
3.「作成」ボタンを押します。
4.確認メッセージが表示されます。再度「作成」を押します。
[手順10] ストリームを開始します。
1.「▶開始」を押します。
2.確認メッセージが表示されます。再度「開始」を押します。
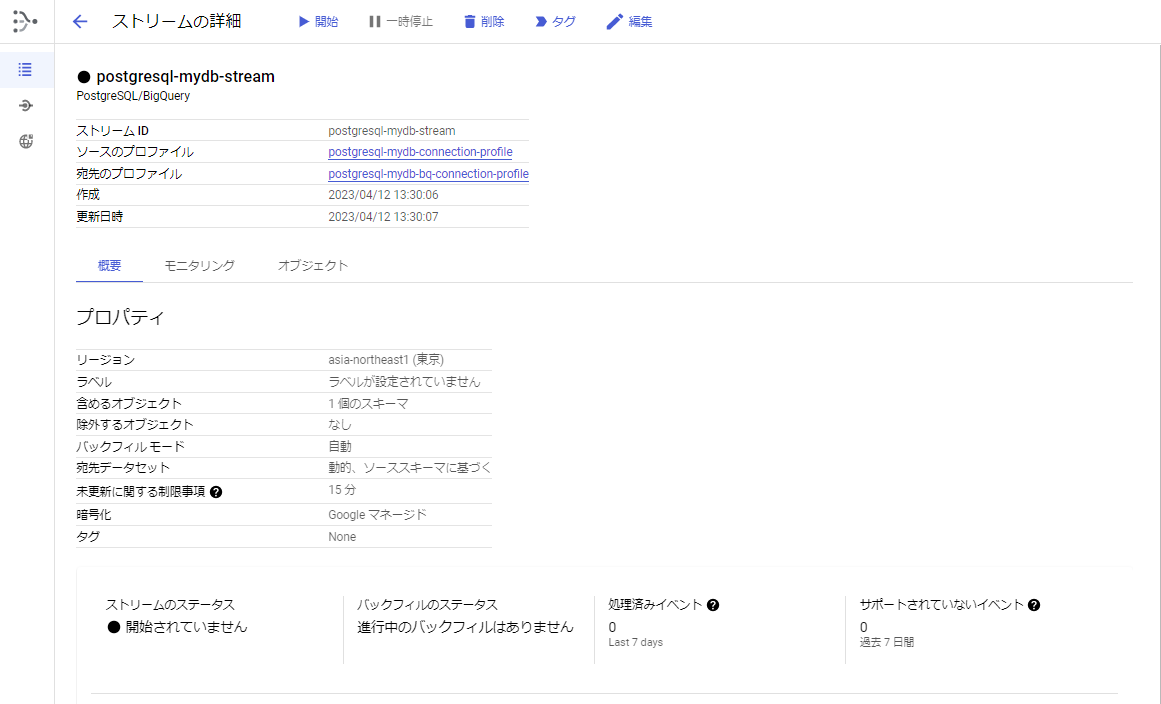
以上で構築できました!
Datastream for BigQueryを試してみる
BigQueryのデータを確認してみた
ストリームを開始してしばらくすると、バックフィルが実行され、BigQueryにデータセットやテーブルの作成、データの取得が行われます。
BigQueryから作成されたテーブルを確認すると、データセットやテーブルが作成されていました。テーブルのカラムには、Datastreamのメタデータが追加されていました。
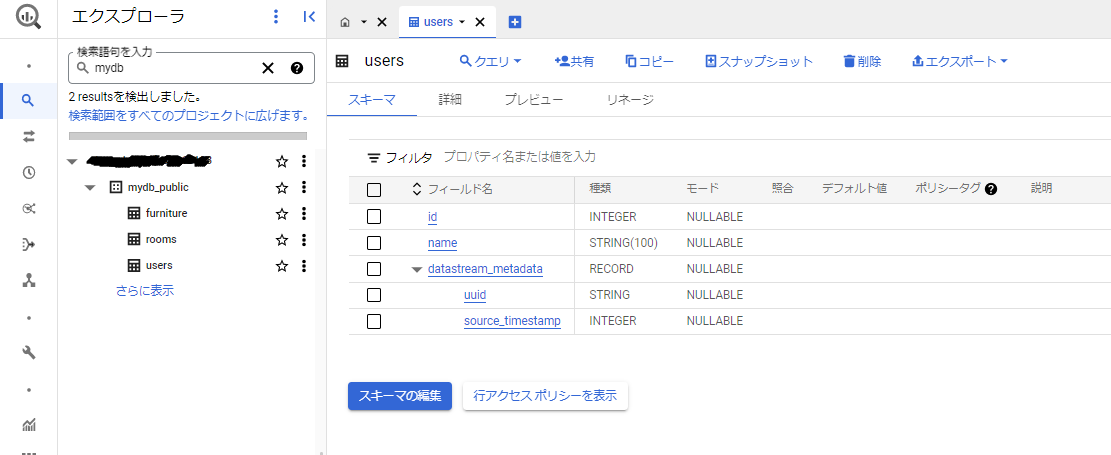
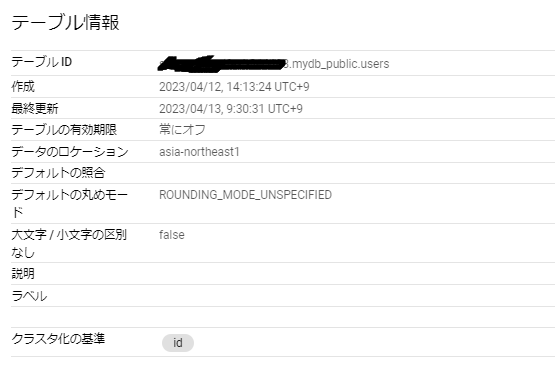
また、id(主キー)に対してクラスタが設定されていました。
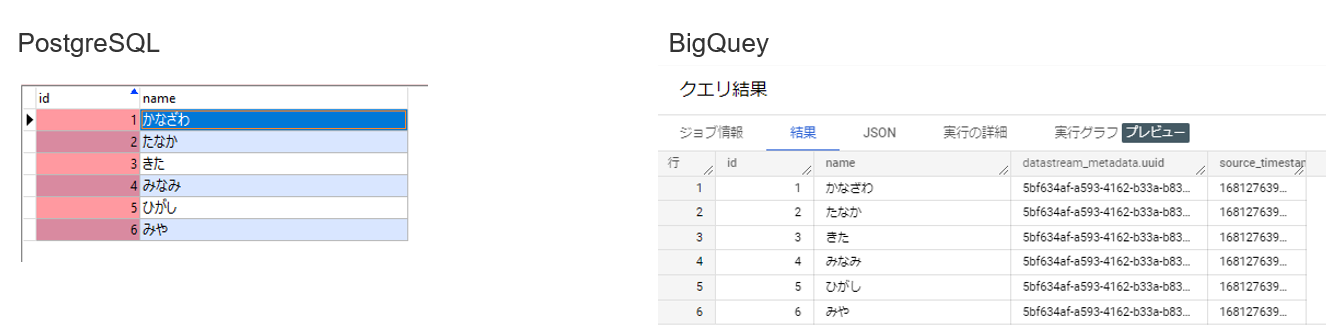
データもBigQueyに複製されていました。
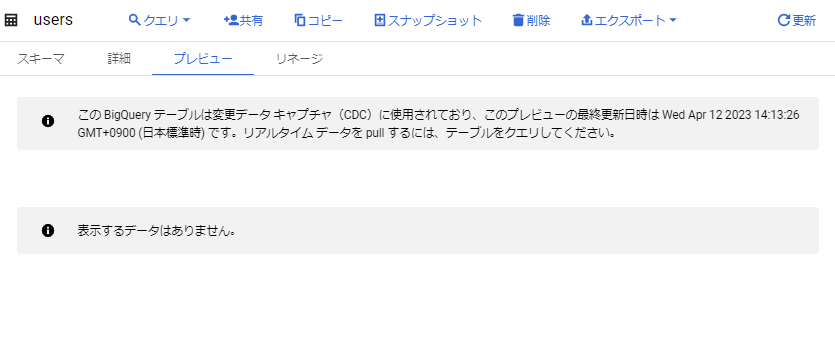
BigQueryワークスペースでテーブルのプレビューを参照すると、通常とは異なるメッセージが表示されました。プレビューの更新は、リアルタイムではないようです。
データの追加・更新・削除を行ってみた
次に、データ追加・更新・削除を行ってみました。
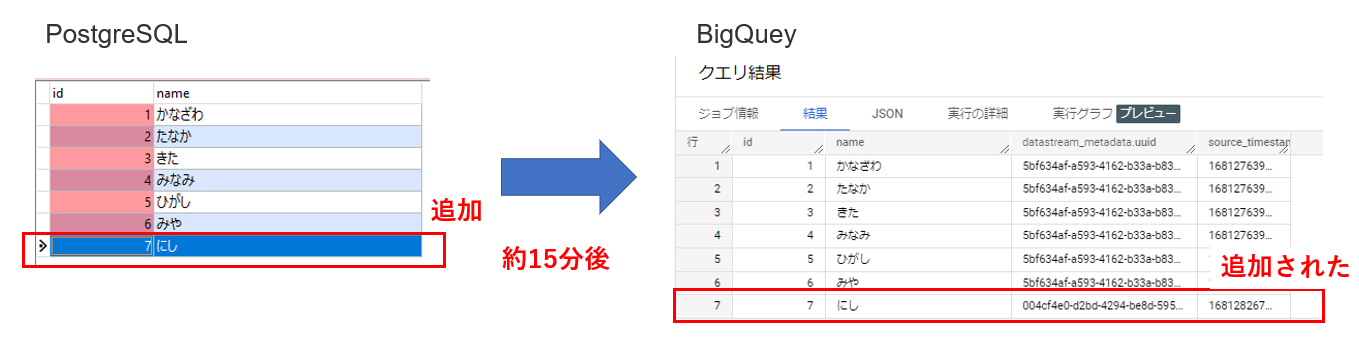
<データ追加>
レコードを1行追加してみました。
約15分後にBigQueryにレコードが追加されていました。
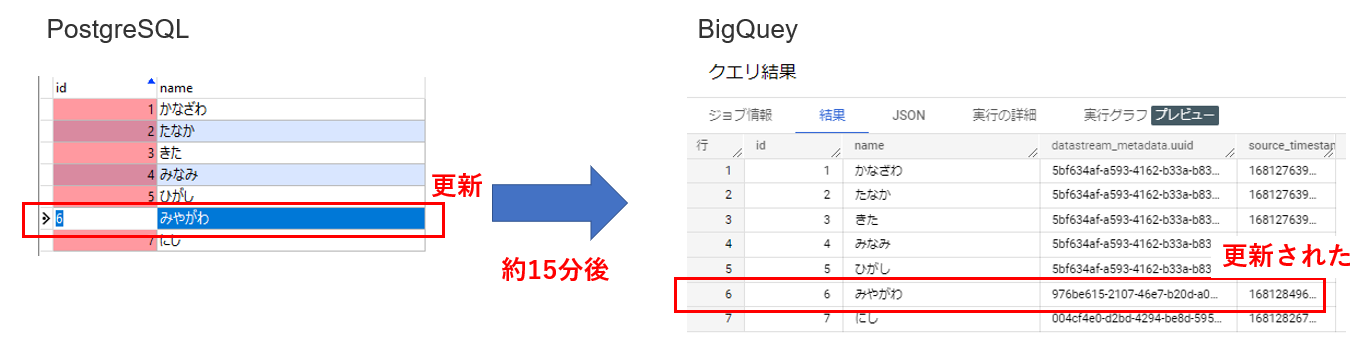
<データ更新>
レコードを1行更新してみました。
約15分後にBigQueryのレコードが更新されていました。
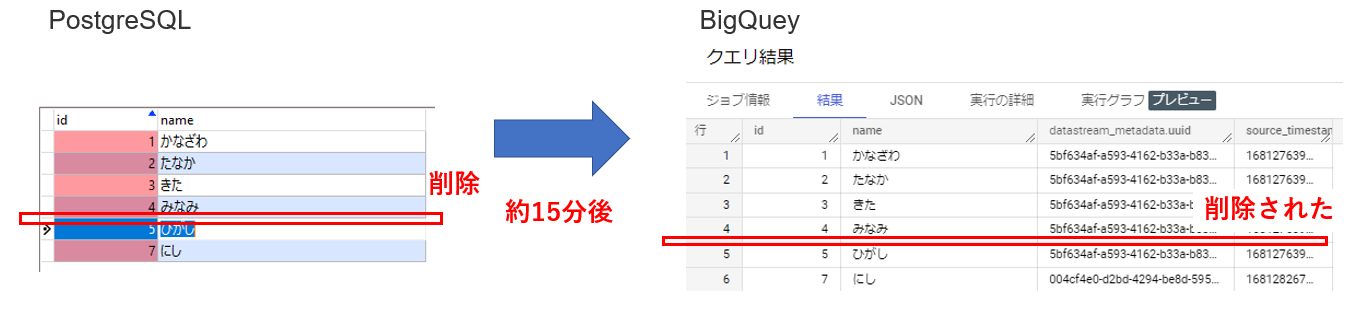
<データ削除>
レコードを1行削除してみました。
約15分後にBigQueryのレコードが削除されていました。
まとめ
PostgreSQLを使って、Datastream for BigQueryを試してみました。
OracleやPostgreSQL、MySQLのデータをBigQueryにレプリケーションできるって聞いたときは、ものすごく驚きました。すごいサービスですよね。自前で構築した場合は、定時バッチを作ったり、データベースから差分のCSVを出力したり、Cloud Storageにファイルを転送したり、BigQueryにファイルを取り込んだり、いろいろ大変です。Datastreamは、データベースのレプリケーション機能を使用するため、導入には考慮が必要ですが、ドキュメントを参照しながら簡単に設定することができました。また、コンソールでの設定も分かりやすく操作できました。
みなさんも是非、使ってみてくださいね。
最後まで、ご覧いただきありがとうございました。
当社、システムサポートは、Google Cloudの導入・移行・運営支援を行っています。
お問い合わせは以下よりお願いいたします。
関連コンテンツ
-
-
author
みやてつ
2012年に新卒で入社して約10年になりました。JavaやPHPなど、レガシーなアプリケーションを中心に開発してきましたが、現在は、AzureやGoogle Cloudなどクラウド技術について勉強中。
2023年6月1日 【Google Cloud】Datastream for BigQueryを使ってみた!








ご意見・ご相談・料金のお見積もりなど、
お気軽にお問い合わせください。